PS6: Set Yourself Free
- Due:
Friday, April 8Friday, April 15 - Notes:
- This problem set is now complete. It is worth 100 points.
- It has been designed in such a way that you can expect 10 points to require approximately 1 hour. Please let me know if this expectation is wrong on particular problems!
- Please keep track of the time estimates for each problem/subproblem.
- Submission:
- In the yourFullName CS251 Spring 2016 Folder, create a Google Doc named yourFullName CS251 PS6.
- For each problem and subproblem, please indicate at the beginning of each writeup approximately how long that problem took you to solve and write up.
- You will create the following code files in this pset:
- Problem 1:
yourAccountName-FunSet.sml - Problem 2:
yourAccountName-OperationTreeSet.sml - Problem 5:
yourAccountName-IntexArgChecker.sml
- Problem 1:
- Include all answers, including copies of relevant code from your
.smlfiles in your PS6 Google Doc. - Drop copies of your
.smlfiles in your~/cs251/drop/ps06drop folder on cs.wellesley.edu.
1. Fun Sets (25 points)
In SML, we can implement abstract data types in terms of familiar structures like lists and trees. But we can also use functions to implement data types. In this problem, you will investigate a compelling example of using functions to implement sets.
You should start by clicking on this link to FunSet.sml to downloadthe skeleton file FunSet.sml. This includes the same SET signature we studied in class:
signature SET =
sig
(* The type of sets *)
type ''a t
(* An empty set *)
val empty : ''a t
(* Construct a single-element set from that element. *)
val singleton : ''a -> ''a t
(* Check if a set is empty. *)
val isEmpty : ''a t -> bool
(* Return the number of elements in the set. *)
val size : ''a t -> int
(* Check if a given element is a member of the given set. *)
val member : ''a -> ''a t -> bool
(* Construct a set containing the given element and all elements
of the given set. *)
val insert : ''a -> ''a t -> ''a t
(* Construct a set containing all elements of the given set
except for the given element. *)
val delete : ''a -> ''a t -> ''a t
(* Construct the union of two sets. *)
val union : ''a t -> ''a t -> ''a t
(* Construct the intersection of two sets. *)
val intersection : ''a t -> ''a t -> ''a t
(* Construct the difference of two sets
(all elements in the first set but not in the second.) *)
val difference : ''a t -> ''a t -> ''a t
(* Construct a set from a list of elements.
Do not assume the list elements are unique. *)
val fromList : ''a list -> ''a t
(* Convert a set to a list without duplicates.
The elements in the resulting list may be in any order. *)
val toList : ''a t -> ''a list
(* Construct a set from a predicate function:
the resulting set should contain all elements for which
this predicate function returns true.
This acts like math notation for sets. For example:
{ x | x mod 3 = 0 }
would be written:
fromPred (fn x => x mod 3 = 0)
*)
val fromPred : (''a -> bool) -> ''a t
(* Convert a set to a predicate function. *)
val toPred : ''a t -> ''a -> bool
(* Convert a set to a string representation, given a function
that converts a set element into a string representation. *)
val toString : (''a -> string) -> ''a t -> string
(* Convert a set to a list without duplicates.
The elements in the resulting list may be in any order. *)
val toList : ''a t -> ''a list
(* Construct a set from a predicate function:
the resulting set should contain all elements for which
this predicate function returns true.
This acts like math notation for sets. For example:
{ x | x mod 3 = 0 }
would be written:
fromPred (fn x => x mod 3 = 0)
*)
val fromPred : (''a -> bool) -> ''a t
(* Convert a set to a predicate function. *)
val toPred : ''a t -> ''a -> bool
(* Convert a set to a string representation, given a function
that converts a set element into a string representation. *)
val toString : (''a -> string) -> ''a t -> string
endYou will be fleshing out the skeleton of the FunSet structure below:
exception Unimplemented (* Placeholder during development. *)
exception Unimplementable (* Impossible to implement *)
(* Implement a SET ADT using predicates to represent sets. *)
structure FunSet :> SET = struct
(* Sets are represented by predicates. *)
type ''a t = ''a -> bool
(* The empty set is a predicate that always returns false. *)
val empty = fn _ => false
(* The singleton set is a predicate that returns true for exactly one element *)
val singleton x = fn y => x=y
(* Determining membership is trivial with a predicate *)
val member x pred = pred x
(* complete this structure by replacing "raise Unimplemented"
with implementations of each function. Many of the functions
*cannot* be implemented; for those, use raise Unimplementable
as there implementation *)
fun isEmpty _ = raise Unimplemented
fun size _ = raise Unimplemented
fun member _ = raise Unimplemented
fun insert _ = raise Unimplemented
fun delete _ = raise Unimplemented
fun union _ = raise Unimplemented
fun intersection _ = raise Unimplemented
fun difference _ = raise Unimplemented
fun fromList _ = raise Unimplemented
fun toList _ = raise Unimplemented
fun fromPred _ = raise Unimplemented
fun toPred _ = raise Unimplemented
fun toString _ = raise Unimplemented
endThe fromPred and toPred operations are based on the observation that a membership predicate describes exactly which elements are in the set and which are not. Consider the following example:
- val s235 = fromPred (fn x => (x = 2) orelse (x = 3) orelse (x = 5));
val s235 = - : int t
- member 2 s235;
val it = true : bool
- member 3 s235;
val it = true : bool
- member 5 s235;
val it = true : bool
- member 4 s235;
val it = false : bool
- member 100 s235;
val it = false : boolThe set s235 consists of exactly those elements satisfying the predicate passed to fromPred – in this case, the integers 2, 3, and 5.
Defining sets in terms of predicates has many benefits. Most important, it is easy to specify sets that have infinite numbers of elements! For example, the set of all even integers can be expressed as:
fromPred (fn x => (x mod 2) = 0)This predicate is true of even integers, but is false for all other integers. The set of all values of a given type is expressed as fromPred (fn x => true). Many large finite sets are also easy to specify. For example, the set of all integers between 251 and 6821 (inclusive) can be expressed as
fromPred (fn x => (x >= 251) && (x <= 6821))Although defining sets in terms of membership predicates is elegant and has many benefits, it has some big downsides. The biggest one is that several functions in the SET signature simply cannot be implemented. You will explore this downside in this problem.
-
(17 points) Flesh out the code skeleton for the
FunSetstructure inFunSet.sml. Some value bindings cannot be implement; for these, useraise Unimplementableas the implementation.Note that
(dfference A B)means all elements in setAthat are not in setB. Earlier versions of this pset mentioned the notion of “symmetric” difference, but that was a bug; what is meant is a one-sided difference, not a symmetric difference.At the end of the starter file are the following commented out test cases. Uncomment these test cases to test your implementation. Feel free to add additional tests.
open FunSet (* range helper function *) fun range lo hi = if lo >= hi then [] else lo::(range (lo + 1) hi) (* Test an int pred set on numbers from 0 to 100, inclusive *) fun intPredSetToList predSet = List.filter (toPred predSet) (range 0 101) val mod2Set = fromPred (fn x => x mod 2 = 0) val mod3Set = fromPred (fn x => x mod 3 = 0) val lowSet = fromList (range 0 61) val highSet = fromList (range 40 101) val smallSet = insert 17 (insert 19 (insert 23 (singleton 42))) val smallerSet = delete 23 (delete 19 (delete 57 smallSet)) (* Be sure to print all details *) val _ = Control.Print.printLength := 101; val smallSetTest = intPredSetToList(smallSet) val smallerSetTest = intPredSetToList(smallerSet) val mod3SetTest = intPredSetToList(mod3Set) val mod2SetUnionMod3SetTest = intPredSetToList(union mod2Set mod3Set) val mod2SetIntersectionMod3SetTest = intPredSetToList(intersection mod2Set mod3Set) val mod2SetDifferenceMod3SetTest = intPredSetToList(difference mod2Set mod3Set) val mod3SetDifferenceMod2SetTest = intPredSetToList(difference mod3Set mod2Set) val bigIntersection = intPredSetToList(intersection (intersection lowSet highSet) (intersection mod2Set mod3Set)) val bigDifference = intPredSetToList(difference (difference lowSet highSet) (difference mod2Set mod3Set))For the test expressions generating lists, the results are as follows:
val smallSetTest = [17,19,23,42] : int list val smallerSetTest = [17,42] : int list val mod3SetTest = [0,3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75, 78,81,84,87,90,93,96,99] : int list val mod2SetUnionMod3SetTest = [0,2,3,4,6,8,9,10,12,14,15,16,18,20,21,22,24,26,27,28,30,32,33,34,36,38,39, 40,42,44,45,46,48,50,51,52,54,56,57,58,60,62,63,64,66,68,69,70,72,74,75,76, 78,80,81,82,84,86,87,88,90,92,93,94,96,98,99,100] : int list val mod2SetIntersectionMod3SetTest = [0,6,12,18,24,30,36,42,48,54,60,66,72,78,84,90,96] : int list val mod2SetDifferenceMod3SetTest = [2,4,8,10,14,16,20,22,26,28,32,34,38,40,44,46,50,52,56,58,62,64,68,70,74,76, 80,82,86,88,92,94,98,100] : int list val mod3SetDifferenceMod2SetTest = [3,9,15,21,27,33,39,45,51,57,63,69,75,81,87,93,99] : int list val bigIntersection = [42,48,54,60] : int list val bigDifference = [0,1,3,5,6,7,9,11,12,13,15,17,18,19,21,23,24,25,27,29,30,31,33,35,36,37,39] : int list -
(8 points) For each function that you declared being unimplementable, explain in English why it is unimplementable. Give concrete examples where appropriate.
2. Operation Tree Sets (25 points)
A very different way of representing a set as a tree is to remember the structure of the set operations empty, insert, delete, union, intersection, and difference used to create the set. For example, consider the set t created as follows:
val s = (delete 4 (difference (union (union (insert 1 empty)
(insert 4 empty))
(union (insert 7 empty)
(insert 4 empty)))
(intersection (insert 1 empty)
(union (insert 1 empty)
(insert 6 empty)))))Abstractly, s is the singleton set {7}. But one concrete representation of s is the following operation tree:
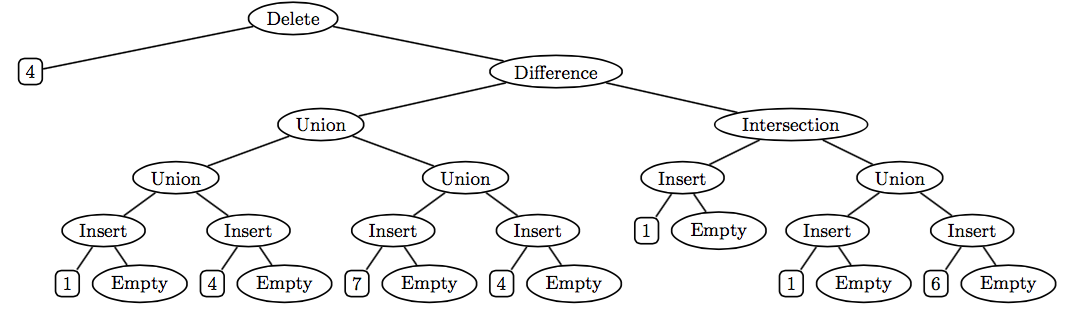
One advantage of using such operation trees to represent sets is that the empty, insert, delete, union, difference, and intersection operations are extremely cheap — they just create a new tree node with the operands as subtrees, and thus take constant time and space! But other operations, such as member and toList, can be more expensive than in other implementations.
In this problem, you are asked to flesh out the missing operations in the skeleton of the OperationTreeSet structure shown below. You should start by clicking on this link to OperationTreeSet.sml to download the skeleton file OperationTreeSet.sml. This includes the same SET signature from class and the FunSet problem above.
structure OperationTreeSet :> SET = struct
datatype ''a t = Empty
| Insert of ''a * ''a t
| Delete of ''a * ''a t
| Union of ''a t * ''a t
| Intersection of ''a t * ''a t
| Difference of ''a t * ''a t
val empty = Empty
fun insert x s = Insert(x,s)
fun singleton x = Insert(x, Empty)
fun delete x s = Delete(x, s)
fun union s1 s2 = Union(s1,s2)
fun intersection s1 s2 = Intersection(s1,s2)
fun difference s1 s2 = Difference(s1,s2)
fun member _ _ = raise Unimplemented
fun toList _ = raise Unimplemented
fun isEmpty _ = raise Unimplemented
fun size _ = raise Unimplemented
fun toPred _ = raise Unimplemented
fun toString eltToString _ = raise Unimplemented
fun fromList _ = raise Unimplemented
fun fromPred _ = raise Unimplementable
endIn the OperationTreeSet structure, the set datatype t is create by constructors Empty, Insert, Delete, Union, Intersection, and Difference. The empty, singleton, insert, delete, union, intersection, difference operations are easy and have been implemented for you. You are responsible for fleshing out the definitions of the member, toList, size, isEmpty, toPred, toString, and fromList operations.
Notes:
-
Your implementation of
membershould not use thetoListfunction. Instead, it should be defined by case analysis on the structure of the operation tree. -
Your
toListfunction should also be defined by case analysis on the structure of the operation tree. Thememberfunction should not be used in the implementation oftoList(because it can be very inefficient). Keep in mind that sets are unordered, and yourtoListfunction may return lists of elements in any order, but it should not have any duplicates. In the first version of this pset, no test case tested duplicate removal intoList. The following case has been added:val dupSet = insert 3 (insert 2 (insert 3 (insert 1 (insert 3 (insert 2 (empty))))))Additionally, this pair should be added to the list named
smallSets:("dupSet", dupSet), -
Your implementation of
sizeandisEmptyshould use thetoListfunction. Indeed, it is difficult to implement these functions by a direct case analysis on the operation tree. Note thatsizewill only work correcty if the output oftoListdoes not contain duplicates. -
In the implementation of
toString, the functionString.concatWithis particularly useful. -
In the implementation of
fromList, for lists with >= 2 elements, you should first split the list into two (nearly) equal-length sublists usingList.takeandList.dropand union the results of turning the sublists into sets. This yields a height-balanced operation tree. -
OperationTreeSet.smlends with two collections of test cases. The first collection involves “small” sets that are defined without usingfromList. The second collection involves “big” sets that are defined usingfromList. The expected outputs to these tests can be found in this transcript file. Because of the way the testing functions are written, the integer elements in the outputs formemberandtoPredwill be in sorted order from low to high, but the integers in the outputs fortoListandtoStringmay be in any order. -
The testing code for most functions (all except for
memberandtoPred) assumes thattoListworks correctly. So you must implementtoListfor for most of the tests to work.
3. Deriving Implementations (15 points)
As we discussed in the Fri. Apr 01 lecture (no foolin), there are two basic reasoning rules involving interpreters, translators (a.k.a. compilers), and program implementation:
The Interpreter Rule (I)
The Translator Rule (T)
Example
For example, we considered the following elements in class:
- a 251-web-page-in-HTML program (i.e., a 251 web page written in HTML)
- an HTML-interpreter-in-C program (i.e., a web browser written in C)
- a C-to-x86-compiler-in-x86 program (i.e., a C-to-x86 compiler written in x86)
- a x86 computer (i.e., an x86 interpreter machine)
They can be used to build a 251 web page display machine as follows:
Feel free to abbreviate by dropping the words “program” and “machine”. “… in …” denotes a program, while “… compiler” and “… translator” denote translator machines and “… interpreter” and “… computer” denote interpreter machines.
Writing Derivations
produces nice derivations with these rules. The mathpartir package is nice, but requires downloading and including an extra file. If you \usepackage{amsmath}, the \cfrac{...}{...} command will also do the job in math mode.
If you do not speak , feel free to use nested bullets to indicate the same structure as the inference rules (though drawn “upside down”). For example, the derivation above could also be written:
- 251 web page machine (I)
- 251-web-page-in-HTML program
- HTML interpreter machine (I)
- HTML-interpreter-in-x86 program (T)
- HTML-interpreter-in-C program
- C-to-x86 compiler machine (I)
- C-to-x86-compiler-in-x86 program
- x86 computer
- x86 computer
- HTML-interpreter-in-x86 program (T)
Questions
- (6 points) John McCarthy was the principal designer of the Lisp language. Steve Russell wrote the first implementations on the IBM 704 computer and made some key observations that simplified the implementation of the language. Time-travel back a few decades and suppose you are given the following:
- a Lisp-interpreter-in-Lisp program (i.e., the
evalfunction); - a Lisp-to-IBM-704-compiler-in-Steve-Russell program (i.e., a Lisp-to-IBM-704 compiler written as instructions for Steve Russell);
- Steve Russell (i.e., a Steve Russell interpreter machine);
- an IBM 704 computer (i.e. an IBM 704 interpreter machine). (This is used in part b, not part a.)
Show how to generate a Lisp-interpreter-in-IBM-704 program. Use the rules to show its derivation. (The correct derivation accurately describes how the first Lisp implementation was created.)
- a Lisp-interpreter-in-Lisp program (i.e., the
-
(1 point) After they helped to produce the Lisp-interpreter-in-IBM-704 program, but before you finished your first Lisp program, John McCarthy moved to Stanford and Steve Russell moved on to video game development. They took the Lisp-interpreter-in-Lisp program and the Steve Russell interpreter machine with them. Fortunately, the IBM 704 computer was too big to move and you kept a copy of the Lisp-interpreter-in-IBM-704 program. Can you still run Lisp programs? How can you build a Lisp machine?1
-
(8 points) Suppose you are given:
- a GraphViz-in-C program
- a C-to-LLVM-compiler-in-x86 program
- an LLVM-to-JavaScript-compiler-in-x86 program
- a JavaScript-interpreter-in-ARM program
- an x86 computer (i.e., an x86 interpreter machine, such as your laptop)
- an ARM computer (i.e., an ARM interpreter machine, such as a smartphone)
Show how to construct a GraphViz machine.
4. Bootstrapping (20 points)
In his Turing Award lecture-turned-short-paper Reflections on Trusting Trust, Ken Thompson describes how a compiler can harbor a so-called “Trojan horse” that can make compiled programs insecure. Read this paper carefully and do the following tasks to demonstrate your understanding of the paper:
-
(10 points) Stage II of the paper describes how a C compiler can be “taught” to recognize
'\v'as the vertical tab character. Using the same kinds of components and processes used in Problem 1, we can summarize the content of Stage II by carefully listing the components involved and describing (by constructing a proof) how a C compiler that “understands” the code in Figure 2.2 can be generated. (Note that the labels for Figures 2.1 and 2.2 are accidentally swapped in the paper.) In Stage II, two languages are considered:- the usual C programming language
- C+\v – an extension to C in which
'\v'is treated as the vertical tab character (which has ASCII value 11).
Suppose we are given the following:
- a C-to-binary compiler (Here, “binary” is the machine code for some machine. This compiler is just a “black box”; we don’t care where it comes from);
- a C+\v-to-binary-compiler-in-C (Figure 2.3 in Thompson’s paper);
- a C+\v-to-binary-compiler-in-C+\v (what should be Figure 2.2 in Thompson’s paper);
- a machine that executes the given type of binary code.
Construct a proof showing how to use the C+\v-to-binary-compiler-in-C+\v source code to create a C+\v-to-binary-compiler-in-binary program.
-
(10 points) Stage III of the paper describes how to generate a compiler binary harboring a “Trojan horse”. Using the same kinds of components and processes used in Problem 1, we can summarize the content of Stage III by carefully listing the components involved and describing (by constructing a proof) how the Trojaned compiler can be generated. In particular, assume we have the parts for this stage:
- a C-to-binary-compiler (again, just a “black box” we are given);
- a C-to-binary-compiler-in-C without Trojan Horses (Figure 3.1 in Thompson’s paper);
- a C-to-binary-compilerTH-in-C with two Trojan Horses (Figure 3.3 in Thompson’s paper);
- a login-in-C program with no Trojan Horse;
- a binary-based computer;
The subscript TH indicates that a program contains a Trojan Horse. A C-to-binary compilerTH has the “feature” that it can insert Trojan Horses when compiling source code that is an untrojaned login program or an untrojaned compiler program. That is, if P is a login or compiler program, it is as if there is a new rule:
The Trojan Horse Rule (TH)
Using these parts along with the two usual rules (I) and (T) and the new rule (TH), show how to derive a Trojaned login program loginTH-in-binary that is the result of compiling login-in-C with a C compiler that is the result of compiling C-to-binary-compiler-in-C. The interesting thing about this derivation is that loginTH-in-binary contains a Trojan horse even though it is compiled using a C compiler whose source code (C-to-binary-compiler-in-C) contains no code for inserting Trojan horses!
5. Static Argument Checking in Intex (15 points)
As described in the lecture slides on Intex, it is possible to statically determine (i.e., without running the program) whether an Intex program contains a argument reference with an out-of-bound index. In this problem you will flesh out skeleton implementations of the two approaches for static argument checking sketched in the slides.
You should start this problem by clicking on this link to Intex.sml to download the Intex implementation file Intex.sml and by clicking on this link to IntexArgChecker.sml to download the skeleton file IntexArgChecker.sml. Rename the latter file to yourAccountName-IntexArgChecker.sml.
-
Bottom-up checker (6 points): In the bottom-up approach, the
checkExpBottomUpfunction returns a pair(min, max)of the minimum and maximum argument indices that appear in an expression. If an expression contains no argument indices, it should return the(valOf Int.maxInt, valOf Int.minInt), which is a pair of SML’s (1) maximum integer and (2) minumum integer. The functionsInt.minandInt.maxare useful for combining such pairs. ThecheckBottomUpfunction on programs returnstrueif all argument references are positive and less than or equal to the programs number of arguments, andfalseotherwise. Complete the following skeleton to flesh out this approach.(* checkBottomUp: pgm -> bool *) fun checkBottomUp (Intex(numargs,body)) = let val (min,max) = checkExpBottomUp body in 0 < min andalso max <= numargs end (* val checkExpBottomUp : Intex.exp -> int * int *) and checkExpBottomUp (Int i) = (valOf Int.maxInt, valOf Int.minInt) | checkExpBottomUp (Arg index) = raise Unimplemented | checkExpBottomUp (BinApp(_,exp1,exp2)) = raise UnimplementedComment out the definition of
bottomUpChecksto test your implementation. -
Top-down checker (7 points): In the top-down approach, the
checkTopDownfunction on a program passes the number of arguments to thecheckExpTopDownfunction on expressions, which recursively passes it down the subexpressions of the abstract syntax tree. When anArgexpression is reached, the index is examined to determine a boolean that indicates whether it is in bounds. The boolean on all subexpressions are combined in the upward phase of recursion to determine a boolean for the whole tree. Complee the following skeleton to flesh out this approach.(* val checkTopDown: pgm -> bool *) fun checkTopDown (Intex(numargs,body)) = checkExpTopDown numargs body (* val checkExpTopDown : int -> Intex.exp -> bool *) and checkExpTopDown numargs (Int i) = raise Unimplemented | checkExpTopDown numargs (Arg index) = raise Unimplemented | checkExpTopDown numargs (BinApp(_,exp1,exp2)) = raise UnimplementedComment out the definition of
topDownChecksto test your implementation. -
Static vs dynamic checking (2 points): A static argument index checker flags programs that might dynamically raise an index-out-of-bounds error, but does not guarantee they will dynamically raise such an error. Give an example of an Intex program for which
checkTopDownandcheckBottomUpreturnsfalsebut does not raise an argument-out-of-bounds error when run on particular arguments. Hint: such a program can raise a different error.
Extra Credit: Self-printing Program (25 points)
In his Turing-lecture-turned-short-paper Reflections on Trusting Trust, Ken Thompson notes that it is an interesting puzzle to write a program in a language whose effect is to print out a copy of the program. We will call this a self-printing program. Write a self-printing program in any general-purpose programming language you choose. Your program should be self-contained — it should not read anything from the file system.
-
A couple decades later, actual physical Lisp Machines became all the rage. We mean “Lisp machine” in the sense given by the rules above, not specifically these hardware Lisp Machines. ↩