
|
CS 332
Assignment 4 Due: Thursday, November 8 |
|
This assignment has two problems on models of recognition, and a third problem on face recognition by the human visual system. The first problem explores a simple version of the alignment method for recognizing 3D objects from 2D image views, and the second examines the performance of the Eigenfaces method to recognize faces, which is based on Principal Component Analysis (PCA). The third problem involves reading papers and watching a video about aspects of face recognition by the human visual system, and writing a summary in preparation for a class discussion on Wednesday, November 7th.
Problem 1: Recognition by Alignment
In this problem, you will complete the implementation of a simple version of the alignment method for recognizing 3D objects that was discussed in class, and apply this method to the problem of recognizing simple 3D wireframe objects. Similar to the paper-and-pencil exercise you completed in class, using the cartoon models of Harry and Henry, the 2D model views and the novel image to be recognized are all related by a simple rotation of a 3D object around a central vertical axis.
To begin, download the /home/cs332/download/alignment folder and set the
Current Folder in MATLAB to this folder. You will complete the definition of the
matchModel function stored in the matchModel.m code file. This file
currently contains only the header of the function.
A GUI program is provided that calls the matchModel function. To run the GUI
program, enter alignGUI in the MATLAB Command Window. When you are done,
click on the close button on the GUI display to terminate the program.
The figure below shows a snapshot of the full program in action, after completion of the
matchModel function:
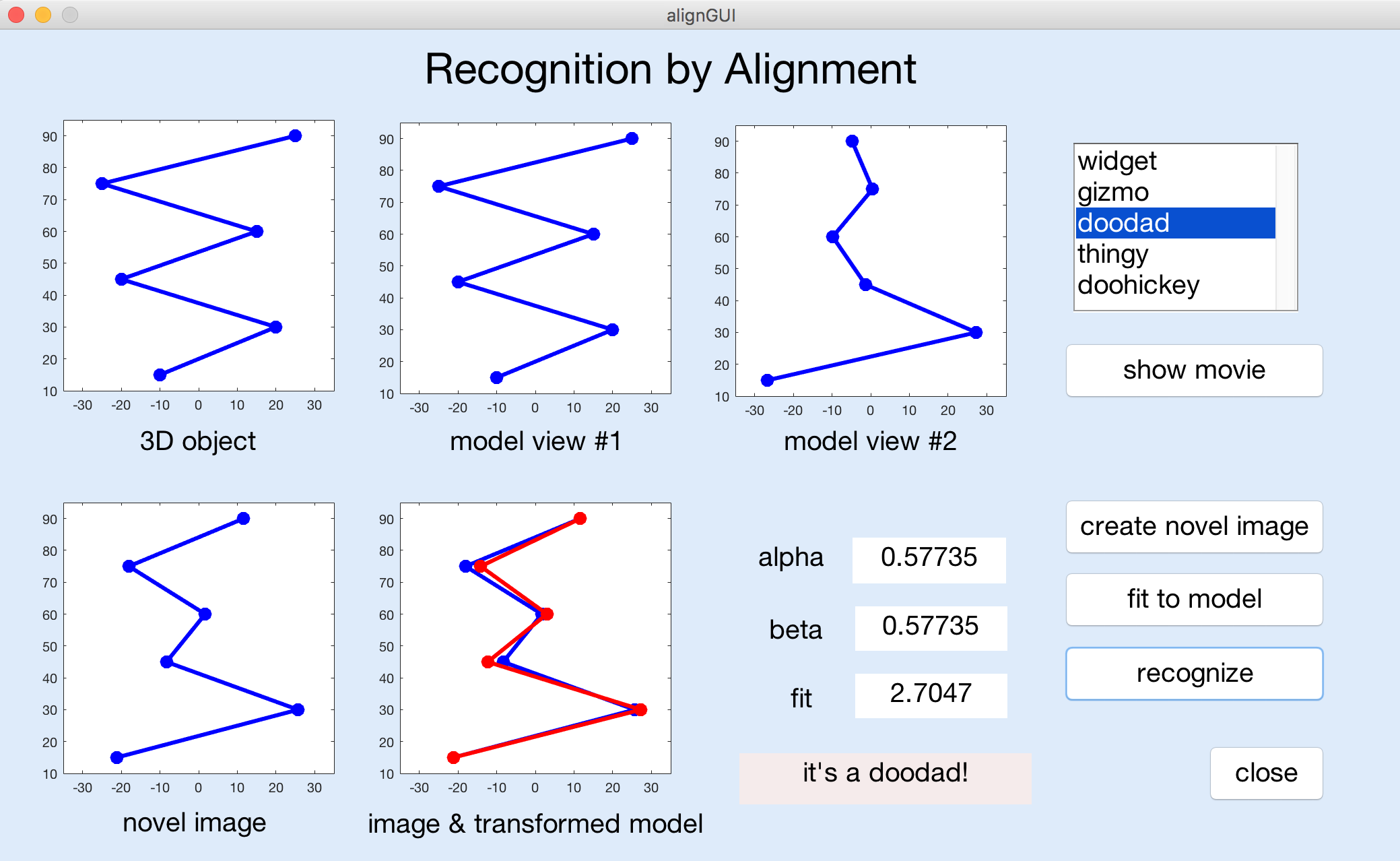
The "objects" in this application are 3D wireframe objects defined by a set of six vertices
(including the endpoints) connected by lines. Each vertex has 3D (x,y,z) coordinates,
but the stored model for each object, which is used for recognition, consists of only the
2D (x,y) coordinates of the vertices as seen in two distinct model views. The two views
are related by a rotation of the 3D coordinates by 60° around a central vertical axis. The
y coordinates (vertical positions) of the six vertices are the same for all five
object models.
Even before completing the matchModel function, you can run the GUI program and
perform the following actions:
- select an object from the listbox in the upper right corner
- click on the "show movie" button
- click on the "create novel image" button
Clicking on the "fit to model" or "recognize" buttons will generate an error that is printed in the Command Window, but the GUI program will continue running. When you select a new object, the two 2D model views of the object will be displayed. The first model view will also be shown in the upper left window. An animation of the object rotating in 3D will appear when you click on the "show movie" button. The "create novel image" button generates and displays a novel view of one of the five model objects, selected at random.
The matchModel function, whose header is shown below, has three inputs
M1, M2, and novel that are each a 6x2 matrix. The first and second
columns of each matrix contain the x and y coordinates, respectively,
for the 6 vertices of the object.
function [alpha, beta, fitVal, fitImage] = matchModel(M1, M2, novel)
This function also has four outputs. alpha and beta are the
coefficients that define the linear combination of the x coordinates of the two
model views, as described in class. fitVal is a measure of how well the image
generated from this linear combination (i.e. the predicted x coordinates of the
vertices) matches the input novel image (i.e. the actual x coordinates stored in
the first column of the input novel matrix). The matchModel function
should use the topmost and bottommost endpoints of the model and novel views to compute
alpha and beta — these are stored in rows 1 and 6 of the
input matrices. The fitVal can be calculated as the mean absolute difference between
the predicted and actual x coordinates for the remaining four vertices (stored in rows
2 to 5 of the input matrices). The output fitImage should be a 6x2 matrix where
the first column contains the x coordinates predicted by the linear combination
of the input model views, and the second column contains the same y coordinates
as those stored in the input matrices.
On the GUI for the alignGUI program, clicking on the "fit to model" button will
call the matchModel function with the currently displayed object model and
novel image, and display the results. Clicking on the "recognize" button will compare the novel
image to all five object models and display the results for the best match.
After completing the definition of the matchModel function, add comments to the
file with answers to the following questions:
- This application assumes that the model views and novel image view are related by the rotation of a 3D object around a central vertical axis. In general, what other kinds of geometric transformations could an object undergo, that would effect its appearance in the image? You need not assume that the object is rigid.
- Suppose you could enhance an alignment method such as this with the idea of parts decomposition, e.g. the ability to define an object as comprised of characteristic subparts. How might this allow you to recognize more complex objects such as a human body?
Submission details: Hand in a hardcopy of your matchModel.m
code file with the answers to the above questions, and drop off an electronic copy of the
code files by logging into the CS file server,
connecting to your alignment folder, and executing the following command:
submit cs332 alignment *.*
Problem 2: Eigenfaces for Recognition
In this problem, you will explore the behavior of the
Eigenfaces
approach to face recognition proposed by Turk and Pentland, which is based on
Principal Component Analysis (PCA).
You do not need to write any code for this problem — you will explore the method with a GUI based program
that a previous CS332 student, Isabel D'Alessandro '18, helped to create. To begin, download the
/home/cs332/download/Eigenfaces folder and set the Current Folder in MATLAB to this folder.
You are welcome to work with a partner on this lab, but should write up your own answers to the questions provided in this handout.
To run the GUI program, enter facesGUI in the MATLAB Command Window. When you are done,
click on the close button on the GUI display to terminate the program.
The figure below shows a snapshot of the program in action:

The program uses an early version of the Yale Face Database that consists of 165 grayscale images (in GIF format) of 15 different people (I'm sorry there is only one woman in the database!). There are 11 images per person, taken under different conditions (central light source or lighting from the left or right; neutral, sad, happy, and surprised expressions; with and without glasses; sleepy and winking). I created two additional images of each person by rotating the neutral-expression images by 15 degrees in the clockwise and counterclockwise directions.
A subset of 7 images for each of the 15 people (omitting the left/right lighting conditions, happy/surprised emotions, and rotated images) is used as the training set to compute the eigenfaces (principal components) that capture the variation across this dataset of face images.
- View the full training set by clicking on the
View Training Datasetbutton. - Click on the
View 25 Eigenfacesbutton to see the top 25 principal components. The first principal component, which captures the largest variation in the data, is shown in the upper left corner, and components that capture progressively less variation (e.g. eigenvectors with smaller eigenvalues) are displayed from left to right within each row, and then from top to bottom. Select two of the eigenfaces and describe in general terms, what features of a face image may be altered if a very large or very small (positive or negative) weight were associated with each of these two eigenfaces. - Click on the
Show Scree Plotbutton to see a scree plot in which the eigenvalues associated with the principal components are displayed as a function of the component number (in decreasing order). The scree plot can be used to assess visually, how many components need to be preserved in order to explain most of the variability in the data. This is shown more directly in the bottom graph that plots the cumulative amount of variation in the data that can be explained as more principal components are considered. How many components are needed to explain at least 90% of the variance of the data?
In class, we showed how an image can be expressed as the sum of an average face
and a weighted sum of a subset of the eigenfaces. If you click the Generate Faces
button, two randomly selected images from the training set will be displayed in the upper left
corner of the GUI. The average face computed from the full training set is shown in the two display
areas at the bottom of the GUI window. In the center, you will see the first eigenface, with the
weights associated with this eigenface, obtained for the two face images shown. The Add
Eigenface button will be enabled, allowing you to incrementally add each eigenface (with
associated weights) to the average faces at the
bottom, using the individual weights for each of the two face images. As you continue to click on the
Add Eigenface button, you will see the two individual identities emerge.
- For a few different pairs of images, observe the evolution of the composite image as more eigenfaces are added, and the different weights for each eigenface associated with each of the two face images (you do not need to record this information, just make a mental note). How many eigenfaces does it typically take to start distinguishing the two faces? How many eigenfaces are typically needed to create an identifiable version of each face?
Once the eigenfaces, or principal components, are computed, we can then try to recognize
the person depicted in a novel image, and examine how the representation generalizes to handle,
for example, different lighting, expressions, and orientations of a face. Using the popup menu to the
right of the Test Set label, you can select one of three different test sets. View the
face images that comprise each test set by making a selection and then clicking the View Test
button (you will see a skinny window with two columns of face images). If you click on the Run
Test button, the
percentage of the test images that are correctly identified will be printed in the text box below this
button. You can also modify the number of eigenfaces that are used to represent each of the
training and test images. Based on the accuracy results obtained for different choices of test set
and number of eigenfaces used, answer the final questions below.
- How well does the method generalize to different lighting conditions? to different emotions? How well does it tolerate small rotations in the image? How do the results depend on the number of eigenfaces used? Over what range do you see improvement in the results (this may vary for the different test sets). Why might you expect to obtain the results that you did? Relate the results to the nature of the information used by the PCA method to perform recognition.
Submission details: Hand in a hardcopy of your answers to the above questions.
Problem 3: Face Recognition in the Human Visual System
During class on Wednesday, November 7, we will have a class discussion about how people recognize faces. The main background for this discussion is the article by Sinha, Balas, Ostrovsky, and Russell entitled, Face Recognition by Humans: Nineteen Results All Computer Vision Researchers Should Know About, which was distributed in an earlier class. You should read this paper in its entirety and be prepared to discuss the basic observations from perceptual studies that are described in the paper, and their implications for the way in which faces may be represented and analyzed in the process of recognition. There are two topics that we will highlight in our discussion, which are addressed in more detail in the video and papers below: (1) the role of holistic processing of faces and (2) the role of average faces in familiar face recognition. For this problem, after reviewing the sources below, write a 1-2 page summary (at least 750 words) on the potential role of holistic processing and face averages in face recognition by humans.
Holistic Processing of Faces:
Lecture video by Nancy Kanwisher on
What you can
learn by studying behavior
Tanaka, J. W. & Simonyi, D. 2016. The "parts and wholes" of face recognition: A review of the literature, The Quarterly Journal of Experimental Psychology 69(10), 1876-1889.
Average Faces in Familiar Face Recognition:
Burton, A. M., Jenkins, R., Hancock, P. J. & White, D. 2005. Robust
representations for face recognition: The power of averages, Cognitive Psychology 51,
256-284.
Submission details: Hand in a hardcopy of your summary for this problem.