How information is represented
Every description of a computer needs to explain how the computer handles information: numbers, text, pictures, sound, movies, instructions.
The computer is an electronic device. Each of its wires can either carry electric current or... not carry current. So, like a light switch, it understands only two states. It turns out that this is enough to make the whole idea work. In fact, any system that can represent at least two states can represent information. Take, for example, the Morse code that is used in telegraphy. Morse is a sound transmission system that can carry a short beep (represented by a dot) and a long beeeeeep (represented by a dash). Any letter or number can be represented by a combination of these two symbols. Click here to see a Morse translator.
Similarly with computers. To represent a number, we use the binary arithmetic system, not the decimal number system that we use in everyday life. In the binary system, any number can be represented using only two symbols, 0 and 1. (Morse is almost, but not quite (due to the pauses between letters) a binary system. A system closely related to Morse is used by computers to do data compression (more about this later). Here is how the binary numbers correspond to our decimal numbers:
| Decimal | Binary |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
| 9 | 1001 |
| 10 | 1010 |
| 11 | 1011 |
| 12 | 1100 |
| 13 | 1101 |
| 14 | 1110 |
| 15 | 1111 |
And so on. Both systems are positional: a great idea that we owe to Arab mathematicians, because before them, counting in Roman was tough (DCCCLXXXII + CXVIII = M, you know...) and counting in Greek was almost impossible (omega pi beta + rho iota eta = alpha).
Positional means that the position of each symbol within the number determines its value. Thus, 32 is different from 23 because the 3 and the 2 are in different positions, and each position has a place value. You already know this, but you do it instinctively, and we are reminding you of this because we will do the same thing with binary numbrs.
For example, you know that the meaning of the number 1492 is:
1492 = 1*1000 + 4*100 + 9*10 + 2*1 = 1*103 + 4*102 + 9*101 + 2*10
Thus the meaning of every digit is defined by the power of 10 in that position.
Similarly, number 1101 in binary means 13 because
13 = 1*8 + 1*4 + 0*2 + 1*1 = 1*23 + 1*22 + 0*21 + 1*20
The numbers 8, 4, 2, 1 are, as you know, powers of 2, starting on the
right and moving left: 1 = 20,
2 = 21,
4 = 21, and 8 = 23
The decimal system is also called "base 10" and the binary "base 2", because every digit in a number contributes to the whole based on the power of 10 (or power of 2) with which it is multiplied.
Of course, we can have positional systems on different bases, like base 12 (AKA "a dozen") and base 7 (AKA a week). Very soon in this course, we'll work with base sixteen.
Below is a form that can help you convert between bytes (8-bit binary
numbers) and decimal numbers easily. Type in a decimal number and
press enter
or click elsewhere on the page to update the
checkboxes. Or, click the checkboxes and watch the decimal number
change. A checked box corresponds to a bit that is one. An
unchecked box corresponds to a
zero. Try creating the number 13 by clicking on the 8, 4, and 1
checkboxes. Play around with this to get comfortable with it.
What's so grand about a positional system? Arithmetic calculations are much easier than in non-positional systems, Can you imagine what second grade would be like if you had to calculate that XLVIII + LXVII = CXV?
Here are some tutorial videos on binary numbers:
- Prof. Kurmas from Grand Valley State University on binary numbers and hex numbers. This is a version he edited for us. Watch the first 5 minutes for today; the rest for next time.
- Someone from Lynda.com on binary numbers. Also about five minutes long.
Fundamental Relationship
One of the key themes of this course is about representations. Computers represent lots of interesting things, such as colors, pictures, music, videos, as well as mundane things like numbers and text, or even complex things like programs. Ultimately, you know that, at the lowest level of all those representations, there are bits.
One of the important aspects of these binary representations is the relationship between the number of bits and the power of the representation. The more bits we have, the more stuff we can represent.
Let's be concrete for just a minute. You saw above that with one bit,
you can number two things: the one labeled "zero" and the one labeled
"one," because there are two possible patterns: {0, 1}. With two bits,
you can number four things, because there are four possible patterns: {
00, 01, 10, 11 }. With three bits, you can number eight
things. (Can you list the eight patterns? Take the four patterns of two
bits and write them twice, once as 0xy and again
as 1xy.) Thus, whenever we use an additional bit, we get
twice as many patterns.
Here's a table of the relationship between the number of bits and the number of patterns:
| Number of Bits | Number of Patterns |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 8 |
| 4 | 16 |
| 5 | 32 |
| 6 | 64 |
| 7 | 128 |
| 8 | 256 |
| ... | |
| 16 | ≈ 65,000 |
| ... | |
| 24 | ≈ 16 million |
| ... | |
| 32 | ≈ 4 billion |
| ... | |
| N | 2N |
This fundamental relationship is important and is also unintuitive, because it is exponential. The last line of the table shows us the N bits yields 2N patterns. This is unintuitive because, if you double the number of bits, you don't get double the number of patterns, you get the square. For example, double 3 bits (8 patterns) to 6 bits, and you get 64 patterns.
We'll see this relationship come up in, for example, our discussion of indexed color, because the limits we place on the number of bits in the representation results in a limit on the number of colors. This is a key idea.
Text Representation
Text is represented with the so-called ASCII code. Years ago, the manufacturers of early computers decided to represent every possible character (visible or invisible, like the space or the newline) with a number. The result was (partially) the code you see below.

A more comprehensive ASCII table is the following, which includes
control characters with their associated graphic symbols, and, for each
character, its hexadecimal, decimal and binary codes:
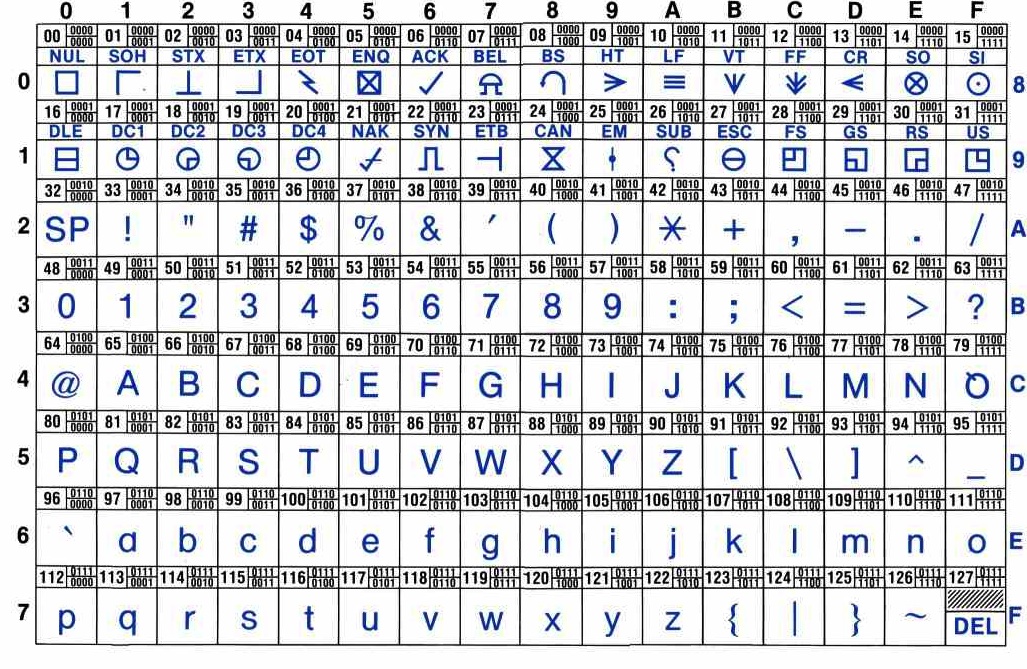
For example the letter E has the ASCII code of 69 and a binary representation of 01000100. The 8 bits are depicted in groups of four, because four bits are used to represent a single digit in the hexadecimal system, that we will discuss later.
The first two rows of the table represent so-called control characters, characters that are not visible, such as backspace (BS), escape (ESC), CR (carriage return - an old word for enter), etc. If you are interested in all acronyms, the AsciiTable website explains them in detail.
Control Characters
You'll notice that the first table above starts with ASCII code 32, which is for the space character. (Yes, even the space character needs to be represented.) The actual ASCII system starts at 0, but the first 32 characters are "control" characters, because they were originally used to control the early printers. For example, the TAB character is ASCII code 9, the line feed character (which moved the paper up) is ASCII code 10, and the carriage return (which moved the print head back to the left edge of the paper) is ASCII code 13. Since those characters are not interesting in the context of this class, we've omitted them from the table.
Line Endings
If all we had to worry about was characters, text representation would be pretty straightforward. However, text is organized into lines, and for historical reasons, one of the subtle differences among Windows, Mac and Unix/Linux is how line endings are represented. In the olden days before Windows, Macs and Unix, the early teletype printers used two control characters at the end of each line: the carriage return character to move the print head back to the left, and the linefeed character to move the paper up by one line.
The Mac represents the end of a line with a carriage return character. Linux uses a line feed character. Windows uses both, just like the olden days.
Usually, when you transfer a text file from system to system, the FTP program (Fetch, WinSCP, or whatever) substitutes the appropriate line ending. The "text mode" of transfer says to make these substitutions; "binary mode" makes no substitutions and is more suitable for non-text files, such as images or programs. Note that HTML and CSS are both kinds of text. Most FTP programs have a "guess which mode" setting that usually works pretty well, but can occasionally make a mistake, which is why it's sometimes useful to know this obscure fact. It's also why copy/pasting between Mac and Windows often fails.
Unicode
The early ASCII system had space for 256 symbols, enough to represent all English characters, punctuation marks, numbers etc. It turns out that there are other languages on Earth besides English, (;-) and recent software is being written to accommodate those, too, via a much larger code called Unicode. We have already been using unicode when putting this tag in our HTML:
<meta charset="utf-8" >
Your Head First HTML & CSS book talks about unicode on page 239.
Bits and Bytes
Groups of bits that are used to represent characters came to be known as a byte. Remember that a byte is 8 bits. That Wikipedia page also discusses the history of the word and the names for larger groups of bytes, such as
- Kilobytes (kB), or 1000 bytes. About a quarter of a page of text.
- Megabytes (MB), or 1000 kilobytes. About 250 small books worth of text.
- Gigabytes (GB), which is 1000 MB. About the amount of text in a small library.
A note on the standard abbreviations
- Uppercase
B
is used for bytes while lowercaseb
is used for bits. Network speeds, where bits go across a wire one at a time, are usually measured in bits per second, or bps. File sizes are always in bytes, hence kB or MB. - The abbreviation for
kilo
is a lowercasek
, hencekB
for kilobytes. The abbreviations for the other prefixes (mega
,giga
,tera
,peta
...) are all uppercase: M, G, T, P ....
Historically, computer scientists have often used kilobyte
to mean 1024 bytes, because 1024 is pretty close to 1000 and because
bytes often come in chunks whose size is a power of 2, and
1024=210. For example, if you buy a 4 GB flash drive, it
won't hold exactly 4 billion bytes, but a bit more because of this
difference. Hard drives and network speeds, on the other hand, are
usually measured in powers of 10 rather than powers of two. In
practice, it rarely matters.
Computers these days come with huge amounts of storage space on the hard drive (often hundreds of GB), but they are usually able to process only a few GB of them at a time (their main memory or RAM). We will use these symbols often in future lectures.