
There is another item associated with each process that it
would be appropriate to mention now: an environment. If
you type printenv into a shell, you'll see the
environemnt associated with your shell process. From within C,
an environment is an array of pointers to character strings,
just like the argv vector, except that each string
is of the form VARIABLE=VALUE (operations are
case-sensitive). A program can get to its environment via the
global variable environ, and environments are
supported by the calls getenv(),
putenv(), setenv(), and
unsetenv(). A particularly important environment
variable is PATH, which provides a list of
directories to search when someone invokes a program.
We think of a process as running the instructions and starting out with the data in a program, and every operating system includes some way to run programs. It would be natural, therefore, to have a system call that takes the name of a file (or a file descriptor), creates a new process, loads the program into the address space, and starts it up. On some operating systems, there is indeed a call to spawn a new process in this way.
The traditional Unix model is a bit different, relying on two
separate types of system calls that, put together, perform this
function. (Actually, modern Unix systems support a
posix_spawn(), but we'll ignore that for now.) The
fork() call creates a new process, but the program
running in the new process is the same as the one that called
fork(): When you fork a new process, the kernel
copies your instruction, data, and stack segments into a new
process. The exec() family of calls (none are
actually called exec(), as we'll see below)
replace the program running in a process with a new
program. No new process is created, the process just runs a
different a program. (You can think of this as being analogous
to a tail call optimization in a compiler.)
Pause and think that through. The only way to run a program
is via exec(), which doesn't create a new process;
and the only way to create a process is fork(),
which doesn't run a new program. (In Linux, fork()
is implemented via a system call called clone(),
but that doesn't affect the general model.)
The usual way, therefore, to launch a program in a new
process is to fork() a new process and then have
the newer fork (the child process) immediately
exec() the program. If you think this seems
unnecessarily difficult, you're right. A lot of impressive
engineering has been invested to make this all work efficiently.
exec()
There is no single exec() call. Rather, there
is a family of exec() system calls that
provides some flexibility in how arguments are passed in and how
the program is looked up. Each call has a one or two character
suffix. The first character is either l, which
means the program's arguments are passed to the
exec() call in the parameter list, or a
v, which means the program's arguments are passed
into the exec() in a single vector (array)
argument. If there is a p in the second position,
it means that the program is to be looked up using the
PATH environment variable. If there is an
e in the second position, that means the caller
wants to pass in an environment explicitly rather than have the
new program inherit the existing environment.
int execv(char *path, char *argv[]);
int execl(char *path, char *arg0, char *arg1,..., (char *)NULL);
int execvp(char *path, char *argv[]);
int execlp(char *path, char *arg0, char *arg1,..., (char *)NULL);
int execve(char *path, char *argv[], char *envv[]);
int execle(char *path, char *arg0, char *arg1,..., (char *)NULL, char *envv[]);
If successful, none of these calls ever return, like calling
a continuation. If they do return, there was an error. In this
case, they return -1 and set errno.
exec() might fail if the file doesn't exist, isn't
a valid executable, or is not executable by the effective user
ID of the current process.
The path is the file to execute. In the
p versions, the path is a file name that will be
searched for in each element of the path list defined by the
PATH environment variable. The program file must
be a valid executable or a shell script. The convention is that
shell script files begin with the characters #!
followed by the pathname of the an interpreter to exectute the
script on the first line.
The argv arguments are just like the
argv parameters every C program gets from the shell
— every program is executed via an exec()
call! Recall what argv usually looks like:
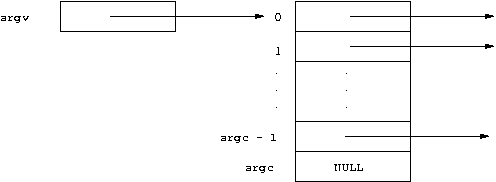
Note: the last element of the argument
vector must be NULL. (Go ahead and check:
argv[argc] actually does exist in your programs,
and its value is always NULL.) The l
variants allow one to specify the paramters without having to
build an array, provided you know how many parameters there are
at compile time. This is slick: on systems where the stacks
grow from low to higher memory addresses, the library doesn't
have to build the vector for the actual kernel call; it just
uses the vector created when your arguments are pushed on the
stack! And so you must remember the NULL here,
too. envv[] indicates a vector of strings
representing variable/value pairs.
Since exec() leaves the process intact, much of
the associated information is preserved. The process ID, real
and effective UIDs and GIDs (unless the program file has set-UID
or set-GID bits on), parent process, times, open file
descriptors are all preserved.
There is a way to say that a file descriptor should be closed
on an exec(). However, it is usually a good idea
to keep track of what files you have open and close them when
you do an exec(), except for standard input,
output, and error, of course.
The text (instructions), data, bss, and stack are
overwritten/reinitialized. Signals are cleared, functions
registered with atexit() are cleared, any shared
memory segments with other processes are unshared, and in
general anything that doesn't make sense in the context of a new
program is not preserved.
Here is an example of an exec() call in action.
The program below (whose source is in
execl-example.c) prints a message including it's
name and process ID, then executes another program (source in
print-pid.c, and then prints another message:
The print-pid program, whose source is below,
just prints out its name and PID:
As you can see from the following script, the message after the
exec() call is never printed, because
exec() never returns. Notice how the program name
is different, but the PID is the same:
Be aware that, for example, I/O buffers will be clobbered by
the new program, and they are not flushed first. You should
always flush your I/O buffers before a call
to exec().
|
fork()
The fork() call creates a new process that is
essentially a clone of the current process (in fact, Linux uses
a clone() call as we said before). The kernel
creates a new address space and copies the instruction and data
segments into that address space (in fact, the instruction
segment is shared). File descriptors are copied, but the file
structures (including the file pointer) are shared.
N.B. The new process is not initialized from a program file.
Each
process has its own stack (the new stack is a copy of the old
one), process ID, process state (including execution times),
and, from the fork() on, its own data.
The fork() call itself is very simple:
pid_t fork(void);
It's operation is straightforward, but understanding how to program with it requires some imagination.
When your program is running in a process, and it executes a
fork(), the result is two separate processes
running your program. The new process does not start the
program from the beginning (remember, all that data you've
computed and state you have accumulated is copied, so
reinitializing would mean reloading the program file). Instead,
the new process starts exececuting at the only reasonable place:
the return from the fork() call!
Your program must account for two separate processes
returning from the fork(). (Which returns first is
unpredictable and depends on the particular process schedule in
your operating system — it may not even be consistent
across programs or runs of the same program.) It would be
unusual for both the parent and child to do exactly the same
thing.
When you write your program, you can distinguish the
processes by the return value of fork(): the new
process, which is a child of the first process, gets back a
0 while the parent process gets back the process ID
of the child. A return value of -1 means the
fork() was unsuccessful, usually because of a lack
of resources or a limit on the number of processes.
Here is a standard example program that uses
fork() (and not much else):
Notice how the line printing the process ID gets executed twice, once by each process. But wait, it appears that the first line executes twice in one run but not in the other? It doesn't actually execute twice, of course. The key to understanding this behavior is the I/O redirection.
When writing to a terminal, the kernel flushes the output
buffers when there is a newline character (something we're all
familiar with by now). But when writing to a file, buffering
takes place in larger units that are a better match to the disk
block size. After the fork(), the child process
gets a copy of all the parent's data, including the unflushed
user-level I/O buffers. When each process exits, it flushes
it's I/O buffers, so each process sends a copy of this data to
disk.
Moral: Be careful about user-level data that will be copied
across a fork(). In particular, you should be
mindful of open files and unflushed I/O buffers. The easest
thing to do is to flush and close open files before forking.
Keep in mind that the child gets a copy of the address space of the parent. (Read only memory, like the text segment, may be shared.) This means that any modifications either process makes to its data is not visible to the other. This is a feature that greatly simplifies concurrent programming with processes (which contrasts sharply with the shared memory model of threads). Generally, this is good from the point of view of software engineering and abstraction. However, questions of efficiency aside, it does mean that it can be difficult for cooperating processes to communicate.
One thing that is shared is the file table entry for any open files. That means that parent and child also share a file pointer for any open files. This is good if you want both processes to write to, for example, a common standard output, standard error, or a log file. You should be careful about I/O however, because there are no guarantees about which process will run when or for how long at a time, so I/O operations can be unpredictably interleaved:
To spawn a process executing a new program, we would code something that looks like this:
...
pid = fork();
if (pid == 0) {
/* use exec() to load a new program over me */
}
/* Parent process finishes up and terminates */
...
Isn't this Monstrously Inefficient?
Implemented in the obvious way, yes. And Unix systems did implement these calls in the obvious way at one time. In this model,fork() is a very expensive (heavy
weight) operation: The kernel must build all the new process
related structures, clone the address space of the parent
process by copying everything into a new address space, then
launch the child process which almost immediately overwrites all
the recently copied data from a program file. This situation
led to a nasty hack (vfork() in BSD Unix) and
provided an added impetus to the development of threads, aka
lightweight processes.
In order to ameliorate the high cost of these primitives in
the common case, Unix systems started to use copy on
write memory pages, which most modern virtual memory
systems support. The idea is that the child process gets a
copy of the parent process's page table, which means that
it actually shares physical memory resources with the parent.
However, the data pages (including the stack) are marked
copy-on-write. As long as a page is only read, there is no
copying. When either process tries to write to a shared page,
it is copied then, and the child process's page table is updated
accordingly. Thus, the fork() call itself only has
to create a new process structure (a task_struct in
Linux) and copy the page table.
In the typical case where the new process calls
exec() almost immediately, few, if any, pages are
written, and therefore, almost no copying takes place.
Why did they do it this way?
I have asked this question a lot. It seems odd to split the common task of spawning a new process into two parts. [Stevens, p. 193] argues that there are two main motivations:-
fork()is quite useful on its own. For example, it is quite common for a network server to have a main process that waits for requests over a network socket. When a request comes in, the server forks. The child processes the request and the parent continues waiting for another request. You will write a similarly structured program in which the parent process reads requests from its input and dispatches child processes to handle the requests. - The two-part model allows the child
process to do some things before calling
exec(). For example, the child may perform I/O redirection or change some other process attributes before having them be inherited across anexec().
Where does it all end?
To understand how a process ends, we need to let you in on a secret about how they begin: In Unix systems, the kernel does not actually start executing your program inmain(). The linker inserts a little bit of startup
code that takes the environment and arguments and then calls
your main(). (Some of the information for this
section was taken from Stevens, Chapter 7.)
When a process ends, it's resources are returned to the kernel, and, usually, its parent its notified. Processes can end normally or abnormally.
Normal Termination
To terminate normally, processes call one of two functions:
void exit(int status);
void _exit(int status);
_Exit(), but that's just the same
as _exit().
We have been using exit() for some time.
exit() calls all exit handlers (registred with
atexit()), then performs I/O cleanup duites
(flushing all buffers), and then calls _exit().
_exit() returns directly to the kernel.
In both cases, open file descriptors are closed and the parent process is notified (and can query the return code).
So, the startup code the linker puts in your program, essentially does this:
exit(main(argc, argv));
[Stevens, p. 162.]
Why would you ever call _exit()? There are
situations in which you actually want to avoid the cleanup
actions implied by exit(). One common case
involves a fork() that doesn't involve a subsequent
exec(). If the parent program had registered exit
handlers, then usually they should only be done once. The
typical strategy is to let the parent do the cleanup and have
the child process call _exit().
There is a lot of energy devoted to this idea of cleaning up
after a program. We know about the most obvious reason: We
normally want to ensure all user-level buffers are flushed
before the process's memory disappears (thus,
the normal cleanup involves the equivalent of an
fclose() on all open files). But it can be handy
for the programmer to be able to specify actions to be performed
however a program terminates. Imagine a database application.
If an error arises and some part of the program calls
exit(), the application may need to undo the
changes it made to the database or ensure that the index
structures are not in an inconsistent state. The way to specify
that you would like something done when your program terminates
is wrap up the activities in a function and register
that function with the atexit() call:
int atexit(void (*function)(void));atexit() uses a function pointer. In this
instance, the parameter named function is a pointer
to a function that takes no arguments ((void)) and
returns no value. A process can register up to 32 such
functions.
Here is an example program that registers two different exit handlers, each one twice:
Notice two things:
- The exit handlers are called once for each time they are registered.
- They are called in reverse order: The last function registered is the first one called.
Abnormal Termination
Abnormal terminination usually results from an error or unhandled interruption. (We'll be talking about signaling a process later.) A process can deliberately create an abnormal termination by usingabort(), which works by
sending the process a SIGABRT:
void abort(void);The Unix Undead
When a process exits, whether abnormally or normally, the kernel reclaims its resources, including its virtual address space, buffers, etc. However, a process descriptor remains in the kernels process list. The structure contains an indication that the process has terminated (its process state) and the exit status.
A terminated process does not completely disappear until someone asks for the return code. A process in this state (in which almost all of its resources are gone but its process descriptor and return code are still there) is called a zombie. Once the parent gets the status (or the system decides no one really cares), the process is completely reclaimed. Collecting the exit statuses so zombie descriptors can be deallocated is called reaping.
Nothing Left but the Waiting
A parent can wait for one of its children to terminate. Indeed, it is not nice to leave zombies around, so one should keep track of allfork()ed processes and collect their return
statuses. There is a family of wait() calls to
support this.
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
wait() blocks until any child terminates. The
terminated child's status is placed in status and
the return value is the process ID of the terminating child.
waitpid() is similar, except that it waits for
the specific process with the given process ID to terminate. If
pid is -1, that means to wait for any
child (like wait()). There are other values that
have to do with restricting the parent's interest to processes
in specific process groups (which we have not yet discussed).
waitpid() also has an option, WNOHANG,
that tells it not to block if a matching child has not
terminated (in which case it returns 0).
We saw above that normal termination involves a final process
status code, and abnormal termination involved a status that
indicated the reason for the termination. (A normal exit code,
specified by the argument to exit(),
_exit(), or by returning from main(),
should be a one byte value.) You can tell from a process's status
whether it terminated normally or abnormally using a collection
of macros that come along with the wait() calls:
WIFEXITED(status)returns true if the process terminated normally (by returning frommain()or callingexit()or_exit()).
WEXITSTATUS(status)returns the least significant byte of the return code of the process provided it terminated normally.
WIFSIGNALED(status)returns true if the process terminated as the result of an uncaught signal.
WTERMSIG(status)returns the number of the signal that caused the process to terminate.
WIFSTOPPED(status)returns true if the process is stopped.
WSTOPSIG(status)returns the number of the signal which caused the child to stop.
Orphaned Processes
A polite program reaps its zombies. But what if a program is impolite or crashes? What happens to its children? A process whose parent has terminated is called an orphan process. In most Unix systems, the kernel finds all children of process that terminates and changed their parent process IDs to1. 1 is the process ID of the
init process, which is said to inherit the
orphaned process. init is the process that is
started immediately after the operating system boots. It brings
the system to a particular run level (e.g., single-user
or multi-user) and then goes through all the runtime
configuration files and starts (via fork() and
exec()) all the appropriate programs.
The init process is polite: any time one of its
children terminates, it performs a wait() so as not
to leave zombies around.
Programming with Processes
One a process has been started, it is off and running on its own. How can multiple processes cooperate to get their work done? You can control what is in a new process's memory when it starts, so, for example, a child process may look in some variable to find out what it should do. For example, a network-based application may fork a process for each request, and each child simply looks in programmer determined variable likecurrent_request to figure out what to do.
This is enough for a surprisingly large number of applications. However, it is often desirable for processes to work together more closely. Perhaps the overhead of starting up a new process is large enough that we don't actually want to fork a process on every request in a network application. (This is also one of the principle motivations for threads, as we shall see later.) In such a case, we would like processes to be able to communicate. Inter-Process Communication (IPC) is a huge topic. In Unix-like systems, there are a range of options for IPC:
- The file system provides the easiest mechanism to use. Given what we saw above about unpredictable ordering of I/O operations, one must be careful with multiple processes using the same file. But disciplined use is fairly straightforward. For example, the parent process can create an output file to which it writes incoming requests. A child processes can read requests from the shared file. As long as their output operations are to different files or are synchronized, everything will work well.
- Pipes are a file-like mechanism supported
by Unix-like operating systems in which one process puts
data into a pipe and another reads it out. You've used
pipes a lot in the shell. (There are
also bi-directional pipes.) Pipes could be implemented in
the file system, but they are actually supported by the
kernel in Unix-like systems: they don't need to create
any disk files, but the data simply goes in and out of
kernel buffers. The relevant system calls are
dup()anddup2(). - FIFOs or named pipes work like regular pipes, but they overcome the restriction that only related processes may use a regular pipe. Named pipes have a name, like a file, so that unrelated processes can open them if they have the right permissions. Unfortunately, FIFOs don't guarantee that multiple readers can work on a single FIFO, i.e., FIFOs were designed with a simple producer/consumer model in mind.
- Message queues are a way for different processes to send arbitrary data to one another. The primary limitation of message queues is that the processes must be on the same machine, and these days, programmers want to plan for the eventuality that cooperating processes may be on different machines.
- Sockets are a mechanism for processes to send messages to each other, but the processes may not be on the same computer (but they can be). The HTTP server is a program that listens for requests on a socket. One downside to programming with sockets is that, if processes really are running on different machines, sending binary data is complicated. Sending text messages is normally fine, but machines can use different representations for other forms of data. A common difference is little endian versus big endian numeric representations. In any case, numeric and structured data must marshalled and unmarshalled.
- Semaphores and locks allow processes to synchronize and to avoid simultaneous manipulation of a shared resource.
- Signals are a simple way communicate a
small amount of information to a process
asynchronously. The kernel sends a process a
signal when certain errors arise (like division by zero).
Users can send a process a signal, often to kill it
(typing
C-cat a shell does this). And processes can signal each other or themselves. Setting an alarm that will alert the process when a certain amount of time has elapsed can be quite useful.
Modified: 31 March 2008