PS6: I Never Metalanguage I Didn't Like
-
Changes from the original PS6 description are highlighed in magenta.
-
This is the final version of PS6, which includes Problem 5 on interpreting and compiling the Condex language.
-
This is the last required regular pset. There will be a PS7, but it will be completely optional.
-
Dueish: Fri Dec 11.
- Notes:
- This pset has 120 total points.
- You can do Problems 1 and 2 based on material through the Thu. Dec. 03 Lec 27 material on symbols and s-expressions.
- You can do Problem 3 based on the Racket PostFix material started in the Fri. Dec. 04 Lec 28 and finished in the Mon. Dec. 07 Lec 29.
- You can do Problem 5a based on the coverage of the
Intex Interpreter in
~/cs251/sml/intex/Intex.smlin Lec 31 on Wed Dec 09. - Problems 4, 5b, and 5c, depend on coverage of the depth-based
Intex-to-PostFix compiler that won’t be finished until the beginning of
Lec 32 on Thu Dec 10, so you might want to wait until after that class to start
these problems. If you’d like to start these problems before then,
look at the discussion of the Intex-to-PostFix compiler at the end of
the Intex slides and/or the implementation of the
Intex-to-PostFix compiler in
~/cs251/sml/intex/IntexToPostFix.sml.- You should complete Problem 4 before starting Parts 5b and 5c on compiling Condex to PostFix.
-
Times (in hours) from some previous semesters:
The following times do not include Problems 2 and 5, which are new problems.
Times Problem 1 Problem 3 Problem 4 Total (w/o Probs 2 and 5!) average time (hours) 0.5 2.5 1.9 4.9 median time (hours) 0.5 2.4 1.8 4.7 25% took more than 0.7 3.0 2.0 5.7 10% took more than 0.8 3.0 3.0 6.8 -
How to Start PS6
- Follow the instructions in the GDoc CS251-F20-T2 Pset Submission Instructions for creating your PS6 Google Doc. Put all written answers and a copy of all code into this PS6 GDoc. If you are working with a partner, only one of you needs to create this document, but you should link it from both of your List Docs.
-
Submission:
- For all parts of all problems, include all answers (including Racket and SML code) in your PS6 google doc. Format Racket and SML code using a fixed-width font, like Consolas or Courier New. You can use a small font size if that helps.
- For Problem 1:
- Be sure that your
deep-reversedefinition inyourAccountName-ps6-deep-reverse.rktalso appears in your PS6 GDoc. - Drop a copy of your
yourAccountName-ps6-deep-reverse.rktin your~/cs251/drop/ps06drop folder oncs.wellesley.edu.
- Be sure that your
- For Problem 2:
- Be sure that the definitions of the four functions
desugar-and,desugar-let*,desugar-cond, anddesugar-begininyourAccountName-ps6-desugaring.rktalso appears in your PS6 GDoc. - Drop a copy of your
yourAccountName-ps6-desugaring.rktin your~/cs251/drop/ps06drop folder oncs.wellesley.edu.
- Be sure that the definitions of the four functions
- For Problem 3:
- Include the modified parts of
yourAccountName-ps6-postfix.rktin your PS6 GDoc. (You only need to include the modified parts, not the entire contents of the PostFix interpreter!) - Drop a copy of your
yourAccountName-ps6-postfix.rktin your~/cs251/drop/ps06drop folder oncs.wellesley.edu.
- Include the modified parts of
- For Problem 4:
- For parts a, b, and d, include a single AST for
P_Intex(from part a) that is annotated with depth information (from part b) and stack information (from part d). - For part c, include the commented PostFix program
P_PostFixthat is the result of translatingP_Intexto PostFix.
- For parts a, b, and d, include a single AST for
- For Problem 5 (all instructions below are new:.
- For Part a:
- Include the definition of
evaland any helper functions in your PS6 GDoc. -
Drop a copy of your
~/cs251/sml/ps6/yourAccountName-Condex.smlfile in your~/cs251/drop/ps06drop folder oncs.wellesley.eduby executing the following (replacing all three occurrences ofgdomeby your cs server username):scp -r ~/cs251/sml/ps6/gdome-Condex.sml gdome@cs.wellesley.edu:/students/gdome/cs251/drop/ps06
- Include the definition of
-
For Part b, include the annotated PostFix program that should result from compiling
lec30Test.cdx, along with the sequence of all intermediate stacks when executing the PostFix program on the two given argument sequences. - For Part c:
- Include the definition of
expToCmdsand any helper functions in your PS6 GDoc. -
Drop a copy of your
~/cs251/sml/ps6/yourAccountName-CondexToPostFix.smlfile in your~/cs251/drop/ps06drop folder oncs.wellesley.eduby executing the following (replacing all three occurrences ofgdomeby your cs server username):scp -r ~/cs251/sml/ps6/gdome-CondexToPostFix.sml gdome@cs.wellesley.edu:/students/gdome/cs251/drop/ps06
- Include the definition of
- For Part a:
1. Deep Reverse (8 points)
We saw in Lec 26 tree recursion on trees represented as s-expressions could be expressed rather elegantly. (See slides 11 & 12 of the Lec 26 slides as well as the video segments on s-expressions and functions on them, the sexp-atoms exercise, and the sexp-height exercise.)
For example:
(define (atom? x)
(or (number? x) (boolean? x) (string? x) (symbol? x)))
(define (sexp-num-atoms sexp)
(if (atom? sexp)
1
(foldr + 0 (map sexp-num-atoms sexp))))
> (sexp-num-atoms '((a (b c) d) e (((f) g h) i j k)))
11
> (sexp-num-atoms '(a b c d))
4
> (sexp-num-atoms 'a)
1
> (sexp-num-atoms '())
0
(define (sexp-atoms sexp)
(if (atom? sexp)
(list sexp)
(foldr append null (map sexp-atoms sexp))))
> (sexp-atoms '((a (b c) d) e (((f) g h) i j k)))
'(a b c d e f g h i j k)
> (sexp-atoms '(a b c d))
'(a b c d)
> (sexp-atoms 'a)
'(a)
> (sexp-atoms '())
'()In this problem, you will define a function (deep-reverse sexp) that returns a new s-expression in which the order of the children at every node of the s-expression tree sexp is reversed.
> (deep-reverse '((a (b c) d) e (((f) g h) i j k)))
'((k j i (h g (f))) e (d (c b) a))
> (deep-reverse '(a b c d))
'(d c b a)
> (deep-reverse 'a)
'a
> (deep-reverse '())
'()Notes:
-
Begin with this starter file ps6-deep-reverse-starter.rkt, which you should rename to
yourAccountName-ps6-deep-reverse.rkt. Add your definition ofdeep-reverseto this file. -
Your definition should have form similar to the definitions for
sexp-num-atomsandsexp-atoms, but you’ll want to use something other thanfoldr. -
You are not allowed to use
reversein your definition.
2. Desugaring Racket (25 points)
How to Start this Problem
Start this problem by copying the
ps6-desugaring-starter.rkt file
into Racket, and renaming the file to yourAccountName-ps6-desugaring.rkt.
As you read the following subsections, you may wish to experiment with
some of the functions they describe, all of which are in
yourAccountName-ps6-desugaring.rkt.
As explained later in the Your Task section, your objective in this problem is to define several one-step desugaring rewrite functions.
Although the explanation for this problem is very long, what you are asked to do is fairly straightforward. The main purpose of this problem is to teach you about how desugaring works, which is a nice illustration of the metalanguage theme of this problem set. After doing this problem, you should have a much better understanding how desugaring works in Racket and other languages.
Background
We have seen that Racket has just a few kernel constructs:
(define Id_name E_defn),
identifiers,
literals (number, booleaans, strings),
if
lambda,
letrec,
quote,
and function calls.
Other Racket constructs are transformed into kernel constructs by a rewriting process called desugaring. Here are some of the desugaring rewrite rules we have seen:
(define (Id_fun Id_param_1 ... Id_param_n) E_body)
=> (define Id_fun (lambda Id_param_1 ... Id_param_n) E_body)
(let {[Id_name_1 E_defn_1] ... [Id_name_n E_defn_n]} E_body)
=> ( (lambda (Id_name_1 ... Id_name_n) E_body)
E_defn_1 ... E_defn_n)
(let* {} E_body) => E_body
(let* {[Id_name_1 E_defn_1] ...} E_body)
=> (let {[Id_name_1 E_defn_1]}
(let* {...} E_body))In a previous version of this pset description,
the above (let* {...} E_body)) incorrectly had let
rather than let*.
(and) => #t
(and E_conjunct) => E_conjunct
(and E_conjunct_1 ...) => (if E_conjunct_1 (and ...) #f)
(or) => #f
(or E_disjunct) => E_disjunct
(or E_disjunct_1 ...) => (let {[Id_fresh E_disjunct_1]}
(if Id_fresh Id_fresh (or ...)))
; where Id_fresh is a ``fresh'' identifier
; not use elsewhere in the program
(begin E_sequent) => E_sequent ; Must have at least one sequent
(begin E_sequent_1 ...) => (let {[Id_fresh E_sequent_1]}
(begin ...))
; where Id_fresh is a ``fresh'' identifier
; not use elsewhere in the program
(cond (else E_body)) => E_body
(cond (E_test_1 E_body_1) ...) => (if E_test_1 E_body_1 (cond ...)In the above rules, the ellipses ... stand for one or more copies of the previous phrase.
E.g. (and E_conjunct_1 ...) refers to an and expression with at least one subexpressions
(called conjuncts); E_conjunct_1 is the first conjunct, and ... stands for
the rest of the conjuncts following E_conjunct_1.
Note some features of these rules:
-
The desugaring of many constructs is defined in terms of one or more base cases and a transformation to a ``smaller” version of the construct. So the rules may need to be applied many times to complete the desugaring. For example:
(and (< a b) (< b c) (< c d)) => ; desugaring rule for (and (a < b) ...) (if (< a b) (and (< b c) (< c d)) #f) => ; desugaring rule for (and (b < c) ...) (if (< a b) (if (< b c) (and (< c d)) #f) #f) => ; desugaring rule for (and (c < d)) (if (< a b) (if (< b c) (< c d) #f) #f) -
Some sugar constructs desugar into other sugar constructs that must themselves be desugared. For example:
(let* {[a (+ x 1)] [b (* a a)]} (list a b)) => ; desugaring rule for (let* {[a (+ x 1)] ...} (list a b)) (let {[a (+ x 1)]} (let* {[b (* a a)]} (list a b))) => ; desugaring rule for (let {[a (+ x 1)]} ...) (let* {[b (* a a)]} ((lambda (a) (let* {[b (* a a)]} (list a b))) (+ x 1)) => ; desugaring rule for (let* {[b (* a a)] ...} (list a b)) ((lambda (a) (let {[b (* a a)]} (let* {} (list a b)))) (+ x 1)) => ; desugaring rule for (let {[b (* a a)]} ...) ((lambda (a) ((lambda (b) (let* {} (list a b))) (* a a))) (+ x 1)) => ; desugaring rule for (let* { } (list a b)) ((lambda (a) ((lambda (b) (list a b)) (* a a))) (+ x 1)) -
Some desugaring need to introduce ``fresh” identifiers that are not used elsewhere in the program. For simplicity, we will imagine that all fresh identifiers have the form
id.posint, where posint is a positive integer, e.g.id.1,id.2, etc., and that programmers do not use identifiers of this form in their programs. For example:(or (< a b) (< b c) (< c d)) => ; desugaring rule for (or (< a b) ...) (let {[id.1 (< a b)]} ; id.1 is a fresh identifier (if id.1 id.1 (or (< b c) (< c d)))) => ; desugaring rule for (let {[id.1 (< a b)]} ...) ((lambda (id.1) (if id.1 id.1 (or (< b c) (< c d)))) (< a b)) => ; desugaring rule for (or (< b c) ...) ((lambda (id.1) (if id.1 id.1 (let {[id.2 (< b c)]} ; id.2 is a fresh identifier (if id.2 id.2 (or (< c d)))))) (< a b)) => ; desugaring rule for (let {[id.2 (< b c)]} ...) ((lambda (id.1) (if id.1 id.1 ((lambda (id.2) (if id.2 id.2 (or (< c d)))) (< b c)))) (< a b)) => ; desugaring rule for (or (< c d)) ((lambda (id.1) (if id.1 id.1 ((lambda (id.2) (if id.2 id.2 (< c d))) (< b c)))) (< a b))
Expressing desugaring rewrite rules as Racket functions that transform s-expressions
The desugaring rewrite rules presented above can be implemented in Racket as transformations on s-expressions that represent Racket syntax. For example, the rule
(let {[Id_name_1 E_defn_1] ... [Id_name_n E_defn_n]} E_body)
=> ( (lambda (Id_name_1 ... Id_name_n) E_body)
E_defn_1 ... E_defn_n)can be implemented by the following desugar-let function:
(define (desugar-let sexp)
(make-call (make-lambda (let-names sexp)
(let-body sexp))
(let-defns sexp)))(This and all functions mentioned in this problem can be found in
yourAccountName-ps6-desugaring.rkt.)
The desugar-let function uses some of the following syntactic abstractions
for let, lambda, and function call expressions:
;;----------------------------------------
;; let expressions have the form
;; (let {[Id_name_1 Id_defn_1]
;; ...
;; [Id_name_n Id_defn_n]}
;; E_body)
;; where n >= 0
(define (make-let names defns body)
(if (and (forall? symbol? names)
(= (length names) (length defns)))
(list 'let
(map (λ (name defn) (list name defn)) names defns)
body)
(error "make-let: malformed let parts"
(list 'let names defns body))))
(define (let-bindings sexp) (second sexp))
(define (let-names sexp) (map first (let-bindings sexp)))
(define (let-defns sexp) (map second (let-bindings sexp)))
(define (let-body sexp) (third sexp))
(define (let? sexp)
(and (list? sexp)
(= (length sexp) 3)
(eq? (first sexp) 'let)
(list (second sexp)) ; must be a list of bindings
(forall? binding? (second sexp))))
(define (binding? sexp) ; name/defn binding, e.g. '(sqr (* a a))
(and (list? sexp)
(= (length sexp) 2)
(symbol? (first sexp))))
;;----------------------------------------
;; lambda expressions have the form
;; (lambda (Id_param_1 ... Id_param_n) E_body)
;; where n >= 0
(define (make-lambda params body)
(if (forall? symbol? params)
(list 'lambda params body)
(error "make-lambda: params aren't all symbols" params)))
(define (lambda-params sexp) (second sexp))
(define (lambda-body sexp) (third sexp))
(define (lambda? sexp)
(and (list? sexp)
(= (length sexp) 3)
(eq? (first sexp) 'lambda)
(list? (second sexp))
(forall? symbol? (second sexp))))
;;----------------------------------------
;; function calls have the form
;; (E_rator E_rand_1 ... E_rand_n)
;; where n >= 0
(define (make-call rator rands)
(if (memq rator '(and begin cond define if lambda
let let* letrec or quote))
(error "make-call: function calls can't begin with core or sugar keyword"
rator)
(cons rator rands)))
(define (call-rator sexp) (first sexp))
(define (call-rands sexp) (rest sexp))
(define (call? sexp)
(and (list? sexp)
(>= (length sexp) 1)
;; Function calls can't begin with core or sugar keyword
(not (memq (first sexp) '(and begin cond define if lambda
let let* letrec or quote)))
))Similarly, the three desugaring rules for transforming or expressions
(or) => #f
(or E_disjunct) => E_disjunct
(or E_disjunct_1 ...) => (let {[Id_fresh E_disjunct_1]}
(if Id_fresh Id_fresh (or ...)))
; where Id_fresh is a ``fresh'' identifier
; not use elsewhere in the program can be implemented by the following desugar-or function
(define (desugar-or sexp)
(let {[disjuncts (or-disjuncts sexp)]}
(cond ((null? disjuncts)
;; (or) => #f
#f)
((= (length disjuncts) 1)
;; (or E) => E
(first disjuncts))
(else
;; (or E ...) => (let {[Id_fresh E]}
;; (if Id_fresh Id_fresh (or ...)))
(let {[fresh (fresh-identifier)]} ;; name fresh identifier so that
;; same identifier is use multiple times
(make-let (list fresh) ; list of one identifier
(list (first disjuncts)) ; list of one defn exp
(make-if fresh
fresh
(make-or (rest disjuncts))))))
)))where desugar-or uses some new syntactic abstractions:
;;----------------------------------------
;; or expressions have the form
;; (or E_disjunct_1 ... E_disjunct_n)
;; where n >= 0
(define (make-or disjuncts) (cons 'or disjuncts))
(define (or-disjuncts sexp) (rest sexp))
(define (or? sexp)
(and (list? sexp)
(>= (length sexp) 1)
(eq? (first sexp) 'or)))The desugar-or function also uses the nullary function fresh-identifier,
which returns a new fresh identifier each time it is called:
> (fresh-identifier)
'id.1
> (fresh-identifier)
'id.2
> (fresh-identifier)
'id.3A desugar function for desugaring Racket epxressions represented as s-expressions
The desugaring rewrite rules presented above just perform one step of the rewriting process. Potentially, such rules may need to be applied many times on many parts of an s-expression in order to completely desugar it.
This processes uses the helper function desugar-rewrite-one-step, which attempts
to apply one desugaring rewrite rule step to the given s-expression sexp:
;;----------------------------------------
;; desugar-rewrite-one-step dispatches to a
;; specialized function for each sugar construct.
;;
(define (desugar-rewrite-one-step sexp)
(cond ((definition? sexp) (desugar-definition sexp))
((let? sexp) (desugar-let sexp))
((let*? sexp) (desugar-let* sexp))
((cond? sexp) (desugar-cond sexp))
((begin? sexp) (desugar-begin sexp))
((and? sexp) (desugar-and sexp))
((or? sexp) (desugar-or sexp))
(else sexp) ; otherwise return expression unchanged
))desugar-rewrite-one-step just determines if sexp is a sugar construct that
can be rewritten.
-
If so, it calls the appropriate function for rewriting that construct, such as the
desugar-letordesugar-orconstructs shown above. -
If not, it simply returns
sexpunchanged.
For example:
> (desugar-rewrite-one-step '(let {[sum (+ a b)] [diff (- a b)]} (/ sum diff)))
'((lambda (sum diff) (/ sum diff)) (+ a b) (- a b))
; complete desugaring in one step
> (desugar-rewrite-one-step '(or (< a b) (< b c) (< c d)))
'(let ((id.1 (< a b))) (if id.1 id.1 (or (< b c) (< c d))))
; partial desugaring in one step
> (desugar-rewrite-one-step '(+ x (* y z)))
'(+ x (* y z))
; unchanged sexp; no desugaring possibleThe desugar function applies desugar-rewrite-one-step as many times as necessary
on an s-expression (and it subtrees) in order to completely transform it by
all the desugaring rules:
(define (desugar sexp)
(let {[dsexp (desugar-rewrite-one-step sexp)]} ; dsexp is the desugared sexp
(if (not (equal? dsexp sexp))
;; then case: a desugaring rewrite rule transformed the top-level sexp
;; to dsexp; iteratively apply desugaring rewrite rules to dsexp
(desugar dsexp))
;; else case: desugaring rules didn't change the top-level sexp,
;; so it must be a kernel sexp; now apply desugaring rules to
;; subtrees of the kernel sexp
(cond ((literal? dsexp) dsexp)
((identifier? dsexp) dsexp)
((definition? dsexp)
(make-definition (definition-name-part dsexp)
(desugar (definition-defn dsexp))))
((if? dsexp)
(make-if (desugar (if-test dsexp))
(desugar (if-then dsexp))
(desugar (if-else dsexp))))
((lambda? dsexp)
(make-lambda (lambda-params dsexp)
(desugar (lambda-body dsexp))))
((call? dsexp)
(make-call (desugar (call-rator dsexp))
(map desugar (call-rands dsexp))))
((letrec? dsexp)
(make-letrec (letrec-names dsexp)
(map desugar (letrec-defns dsexp))
(desugar (letrec-body dsexp))))
(else (error "Unhandled expression" dsexp))
))))desugar first applies desugar-rewrite-one-step on the given s-expression sexp to yield dsexp.
-
If
dsexpis different fromsexp, it is iteratively desugared by callingdesugarondsexp. This handles cases like desugaringor, which yields aletexpression that itself needs to be desugared. -
If
dsexpis the same assexp, then the desugaring rules have not made any transformations to the whole s-expressionsexp. This means it must be a kernel expression. But it might still be necessary to desugar the subtrees of this kernel expression. For example, this conditional expression has parts that need desugaring:(if (or (< a b) (< b c)) (* a b) (let {[c (+ a b)]} (* c c)))So
desugaris recursively applied to each of the subtrees of the kernel expression.The base cases of this recursive processing are the leaves of kernel expresssions — i.e., identifiers (variable references) and literal values (numbers, booleans, strings, and quoted symbols/lists). These leaves are unchanged by the desugaring process
Here’s some examples of desugar in action:
> (desugar '(let {[sum (+ a b)] [diff (- a b)]} (/ sum diff)))
'((lambda (sum diff) (/ sum diff)) (+ a b) (- a b))
; performed just one rewrite step to complete desugaring
> (desugar '(or (< a b) (< b c) (< c d)))
'((lambda (id.1) (if id.1 id.1 ((lambda (id.2) (if id.2 id.2 (< c d))) (< b c)))) (< a b))
; performed many rewrite steps to complete desugaring
> (desugar '(if (or (< a b) (< b c)) (* a b) (let {[c (+ a b)]} (* c c))))
'(if ((lambda (id.2) (if id.2 id.2 (< b c))) (< a b)) (* a b) ((lambda (c) (* c c)) (+ a b)))
; performed rewrite steps on then and else clauses of `if` to complete desugaring
> (desugar '(+ x (* y z)))
'(+ x (* y z))
; performed no rewrite stepsIn order to help you understand the step-by-step rewriting nature of the desugaring
rewrite rules, in the case where dsexp is not equal to sexp, the desugar function
displays some tracing information if the flag show-one-step-desugarings? is #t:
(define show-one-step-desugarings? #t) ; controls tracing within desugar
(define (desugar sexp)
(let {[dsexp (desugar-rewrite-one-step sexp)]} ; dsexp is the desugared sexp
(if (not (equal? dsexp sexp))
;; then case: a desugaring rewrite rule transformed the top-level sexp
;; to dsexp; iteratively apply desugaring rewrite rules to dsexp
(begin (if show-one-step-desugarings?
;; show details of one-step rewriting in this case
(begin (printf "desugar-rewrite-one-step:\n")
(pretty-display sexp)
(printf "=> ")
(pretty-display dsexp)
(printf "\n"))
'do-nothing)
(desugar dsexp))
;; else case is unchanged from aboveBelow are the above examples of desugar with show-one-step-desugarings? turned on:
> (desugar '(let {[sum (+ a b)] [diff (- a b)]} (/ sum diff)))
desugar-rewrite-one-step:
(let ((sum (+ a b)) (diff (- a b))) (/ sum diff))
=> ((lambda (sum diff) (/ sum diff)) (+ a b) (- a b))
'((lambda (sum diff) (/ sum diff)) (+ a b) (- a b))> (desugar '(or (< a b) (< b c) (< c d)))
desugar-rewrite-one-step:
(or (< a b) (< b c) (< c d))
=> (let ((id.3 (< a b))) (if id.3 id.3 (or (< b c) (< c d))))
desugar-rewrite-one-step:
(let ((id.3 (< a b))) (if id.3 id.3 (or (< b c) (< c d))))
=> ((lambda (id.3) (if id.3 id.3 (or (< b c) (< c d)))) (< a b))
desugar-rewrite-one-step:
(or (< b c) (< c d))
=> (let ((id.4 (< b c))) (if id.4 id.4 (or (< c d))))
desugar-rewrite-one-step:
(let ((id.4 (< b c))) (if id.4 id.4 (or (< c d))))
=> ((lambda (id.4) (if id.4 id.4 (or (< c d)))) (< b c))
desugar-rewrite-one-step:
(or (< c d))
=> (< c d)
'((lambda (id.3) (if id.3 id.3 ((lambda (id.4) (if id.4 id.4 (< c d))) (< b c)))) (< a b))
>> (desugar '(if (or (< a b) (< b c)) (* a b) (let {[c (+ a b)]} (* c c))))
desugar-rewrite-one-step:
(or (< a b) (< b c))
=> (let ((id.5 (< a b))) (if id.5 id.5 (or (< b c))))
desugar-rewrite-one-step:
(let ((id.5 (< a b))) (if id.5 id.5 (or (< b c))))
=> ((lambda (id.5) (if id.5 id.5 (or (< b c)))) (< a b))
desugar-rewrite-one-step:
(or (< b c))
=> (< b c)
desugar-rewrite-one-step:
(let ((c (+ a b))) (* c c))
=> ((lambda (c) (* c c)) (+ a b))
'(if ((lambda (id.5) (if id.5 id.5 (< b c))) (< a b)) (* a b) ((lambda (c) (* c c)) (+ a b)))
>> (desugar '(+ x (* y z)))
'(+ x (* y z)) ; desugar-rewrite-one-step doesn't change any s-expressions in this exampleYour task
The file yourAccountName-ps6-desugaring.rkt that you copied from the
ps6-desugaring-starter.rkt file
contains all the code describe above.
It includes correct implementations of the the following functions for
one-step desugaring rewriting rules that are used in desugar-rewrite-one-step:
desugar-definitiondesugar-letdesugar-or
Your goal is to flesh out the skeletons for the other four desugaring functions
(shown below) so that they correctly express the associated rewrite rules.
These skeletons appear in yourAccountName-ps6-desugaring.rkt
below this header:
;;%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
;; FOR PS6 PROBLEM 2, WRITE YOUR SOLUTIONS BELOW:
;;%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%-
desugar-and;; desugar-and should implement these three desugaring rules ;; ;; 1. (and) => #t ;; ;; 2. (and E) => E ;; ;; 3. (and E ...) => (if E (and ...) #f) ;; (define (desugar-and sexp) 'flesh-out-desugar-and)Some examples:
> (desugar-and '(and)) #t > (desugar-and '(and (< a b))) '(< a b) > (desugar-and '(and (< a b) (< b c) (< c d))) '(if (< a b) (and (< b c) (< c d)) #f)Notes:
-
You should not use the
and?predicate indesugar-and. The argumentsexptodesugar-andis already guaranteed to be anands-expression because(desugar-and sexp)is called bydesugar-rewrite-one-steponly in the case where(and? sexp)is true. -
You should call the syntax functions
and-conjuncts,make-if, andmake-andin the body ofdesugar-and.-
and-conjunctsreturns the list of subexpressions of theandconstruct, which are known as conjuncts. -
You should use the usual list operations
null?,first,rest, andlengthto manipulate the list of conjuncts.
-
-
You can test all 3 above cases using
(test-desugar-and).
-
-
desugar-let*;; desugar-let* should implement these two desugaring rules ;; ;; 1. (let* { } Ebody) => Ebody ;; ;; 2. (let* {[Id1 E1] ...} Ebody) ;; => (let {[Id1 E1]} ;; (let* {...} Ebody)) ;; (define (desugar-let* sexp) 'flesh-out-desugar-let*)Some examples:
> (desugar-let* '(let* {} (list a b))) '(list a b) > (desugar-let* '(let* {[b (* a a)]} (list a b))) '(let ((b (* a a))) (let* () (list a b))) > (desugar-let* '(let* {[a (+ x 1)] [b (* a a)]} (list a b))) '(let ((a (+ x 1))) (let* ((b (* a a))) (list a b)))Note:
-
You should not use the
let*?predicate indesugar-let*. The argumentsexptodesugar-let*is already guaranteed to be alet*s-expression because(desugar-let* sexp)is called bydesugar-rewrite-one-steponly in the case where(let*? sexp)is true. -
You should call the syntax functions
let*-names,let*-defns,let*-body,make-let, andmake-let*.-
Both
let*-namesandlet*-defnsreturn lists that you should manipulate via the usual list operationsnull?,first, andrest. -
Both
make-letandmake-let*expect their first and second arguments (names and defns, respectively) to belists .
-
-
You can test all 3 above cases using
(test-desugar-let*).
-
-
desugar-cond;; desugar-cond should implement these two desugaring rules ;; ;; 1. (cond (else E)) => E ;; ;; 2. (cond (Etest Ebody) ...) => (if Etest Ebody (cond ...)) ;; (define (desugar-cond sexp) 'flesh-out-desugar-cond)Some examples (you can test all 3 cases using
(test-desugar-cond)):> (desugar-cond '(cond (else (- a b)))) '(- a b) > (desugar-cond '(cond ((= a b) (* a b)) (else (- a b)))) '(if (= a b) (* a b) (cond (else (- a b)))) > (desugar-cond '(cond ((< a b) (+ a b)) ((= a b) (* a b)) (else (- a b)))) '(if (< a b) (+ a b) (cond ((= a b) (* a b)) (else (- a b))))Notes:
-
You should not use the
cond?predicate indesugar-cond. The argumentsexptodesugar-condis already guaranteed to be aconds-expression because(desugar-cond sexp)is called bydesugar-rewrite-one-steponly in the case where(cond? sexp)is true. -
You should not use the
cond-clauses?predicate indesugar-cond. This is just a helper function used in the definitions ofcond?ofmake-cond. -
You should call the syntax functions
cond-clauses,make-if, andmake-cond.-
cond-clausesreturns a list of all clauses of thecondconstruct. You should manipulate this list of clauses via the usual list operationslength,first, andrest. -
The two parts of each clause (known as the test and body) should be accessed using the syntax functions
cond-clause-testandcond-clause-body. -
The syntactic abstractions for
condguarantee that it has at least one clause, and that the last clause must have a test part that iselse. So you don’t need to check that the clauses are nonempty, and you don’t need to check that the test part of clause iselsewhen there’s only one clause.
-
-
You can test all 3 above cases using
(test-desugar-cond).
-
-
desugar-begin;; desugar-begin* should implement these two desugaring rules ;; ;; 1. (begin E) => E ;; ;; 2. (begin E1 ...) => (let {[Id_fresh E1]} (begin ...) ;; ;; Note: use (fresh-identifier) to generate Id_fresh ;; (define (desugar-begin sexp) 'flesh-out-desugar-begin)Some examples (you can test all 3 cases using
(test-desugar-begin)):> (desugar-begin '(begin (+ x y))) '(+ x y) > (desugar-begin '(begin (printf "y is ~a\n" y) (+ x y))) '(let ((id.1 (printf "y is ~a\n" y))) (begin (+ x y))) ; Your fresh id might differ > (desugar-begin '(begin (printf "x is ~a\n" x) (printf "y is ~a\n" y) (+ x y))) '(let ((id.2 (printf "x is ~a\n" x))) (begin (printf "y is ~a\n" y) (+ x y))) ; Your fresh id might differNotes:
-
You should not use the
begin?predicate indesugar-begin. The argumentsexptodesugar-beginis already guaranteed to be abegins-expression because(desugar-begin sexp)is called bydesugar-rewrite-one-steponly in the case where(begin? sexp)is true. -
You should call the syntax functions
begin-sequents,make-let,make-begin, andfresh-identifier.-
begin-sequentsreturns a list of all subexpressions of thebeginconstruct, which are known as sequents You should manipulate this list of sequents via the usual list operationslength,first, andrest. -
The syntactic abstractions for
beginguarantee that it has at least one sequent, so you don’t need to check that the sequents are nonempty -
Recall from above that the first two arguments (names and defns) of
make-letmust belists . -
As illustrated in
desugar-or, use the call(fresh-identifier)to generate a fresh-identifier. Because the call(fresh-identifier)is stateful and generates a different new fresh identifier every time it is called, your test cases might have different fresh identifiers than in the above examples.
-
-
You can test all 3 above cases using
(test-desugar-begin).
-
General Notes:
-
In all your definitions, you should use apppropriate syntactic abstractions, which are defined in the section of
yourAccountName-ps6-desugaring.rktthat begins:;;;**************************************************************************** ;;; Syntactic abstractions -
Carefully study the working functions
desugar-letanddesugar-oras examples of one-step desugaring rewrite rules. -
Use
(test-all)to run all testers for this problem. -
A beautiful aspect of this desugaring framework is that, once your one-step desugaring rewrite functions are working, the
desugarfunction can use them to completely desugar any s-expresions containing them, possibly used together with other sugar constructs. For example:;; These examples are shown with (define show-one-step-desugarings? #f) ;; but you can try them with this flag set to #t > (desugar '(and (< a b) (< b c) (< c d))) '(if (< a b) (if (< b c) (< c d) #f) #f) > (desugar '(let* {[a (+ x 1)] [b (* a a)]} (list a b))) '((lambda (a) ((lambda (b) (list a b)) (* a a))) (+ x 1)) > (desugar '(cond ((< a b) (+ a b)) ((= a b) (* a b)) (else (- a b)))) '(if (< a b) (+ a b) (if (= a b) (* a b) (- a b))) > (desugar '(begin (printf "x is ~a\n" x) (printf "y is ~a\n" y) (+ x y))) '((lambda (id.2) ((lambda (id.3) (+ x y)) (printf "y is ~a\n" y))) (printf "x is ~a\n" x))desugarshould even work on large s-expresions that combine all seven syntactic sugar constructs, like this one:(define big-sexp '(define (test-repl prompt done) (begin (printf "~a x>" prompt) (let {[x (read)]} (if (equal? x done) 'repl-done (begin (printf "~a y>" prompt) (let* {[y (read)] [result (cond ((or (< x y) (> y 100) (and (< 10 x) (< y (* 2 x)) (< y 50))) (let* {[a (+ x y)] [b (* x a)] [c (/ a b)]} (list x y a b c))) ((and (> x y) (> (* 3 x) y)) (list x y (* y y))) (else (list x y)))]} (begin (printf "Result is ~a\n" result) (test-repl prompt done))))))))) (desugar big-sexp) '(define test-repl ; this s-expression was manually reformatted by Lyn to be more readable (lambda (prompt done) ((lambda (id.1) ((lambda (x) (if (equal? x done) 'repl-done ((lambda (id.2) ((lambda (y) ((lambda (result) ((lambda (id.3) (test-repl prompt done)) (printf "Result is ~a\n" result))) (if ((lambda (id.4) (if id.4 id.4 ((lambda (id.5) (if id.5 id.5 (if (< 10 x) (if (< y (* 2 x)) (< y 50) #f) #f))) (> y 100)))) (< x y)) ((lambda (a) ((lambda (b) ((lambda (c) (list x y a b c)) (/ a b))) (* x a))) (+ x y)) (if (if (> x y) (> (* 3 x) y) #f) (list x y (* y y)) (list x y))))) (read))) (printf "~a y>" prompt)))) (read))) (printf "~a x>" prompt))))Since
big-sexpand the result of desugaring it are both s-expressions for Racket function definitions, you can remove the quote mark on them, and give them as inputs to the Racket interpreter to define a functiontest-repl. You can then verify that the behavior of the function before and after desugaring is the same!
3. Extending PostFix (34 points)
In lecture we studied several different versions of an interpreter for the PostFix language implemented in Racket. (See the materials from Lec 28 and Lec 29, especially the slides for the PostFix Interpreter in Racket and the associated videos.)
This problem involves starting with the following version of the interpreter:
This is a slightly modified version of the file postfix-transform-fancy.rkt studied in lecture.
Begin by making a copy of ps6-postfix-starter.rkt named yourAccountName-ps6-postfix.rkt and load this into Dr. Racket. Near the bottom of this file is the following PostFix program named sos (for “sum of squares”). Racket’s semi-colon comments have been used to explain the commands in the program:
;; Sum-of-squares program
(define sos
'(postfix 2 ; let's call the arguments a and b, from top down
1 nget ; duplicate a at top of stack
mul ; square a
swap ; stack now has b and a^2 from top down
1 nget mul ; square b
add ; add b^2 + a^2 and return
))Let’s run the program on the arguments 5 and 12:
> (postfix-run sos '(5 12))
About to execute commands (1 nget mul swap 1 nget mul add) on stack (5 12)
after executing 1, stack is (1 5 12)
after executing nget, stack is (5 5 12)
after executing mul, stack is (25 12)
after executing swap, stack is (12 25)
after executing 1, stack is (1 12 25)
after executing nget, stack is (12 12 25)
after executing mul, stack is (144 25)
after executing add, stack is (169)
169Note that the stack that results from executing each command on the previous stack is displayed, line by line. This behavior is controlled by the display-steps? flag at the top of the program:
(define display-steps? #t)If we set the flag to #f, the intermediate stack display will be turned off:
(define display-steps? #f)> (postfix-run sos '(5 12))
169Turn the display-steps? flag on when it’s helpful to understand or debug a PostFix program.
-
(10 points)
Consider the following Racket function
gthat is defined near the bottom of the PostFix interpreter file:(define (g a b c) (- c (if (= 0 (remainder a 2)) (quotient b (- a c)) (* (+ b c) a))))In this part, your goal is to flesh out the definition of a three-argument PostFix program
pfgthat performs the same calculation asgon three arguments:(define pfg '(postfix 3 ;; Flesh out and comment the commands in this PostFix program ))Here are some examples with a correctly defined
pfg:> (apply g '(10 2 8)) 7 > (postfix-run pfg '(10 2 8)) 7 > (apply g '(-7 2 3)) 38 > (postfix-run pfg '(-7 2 3)) 38 > (apply g '(5 4 5)) -40 > (postfix-run pfg '(5 4 5)) -40Notes:
-
Please comment the commands in
pfglike those insos. -
You have been provided with a testing function
(test-pfg)that will test yourpfgfunction on 5 sets of arguments:;; Tests on an incorrect definition of pfg: > (test-pfg) Testing pfg on (10 2 8): ***different results*** g: 7 pfg: -7 Testing pfg on (11 2 8): ***different results*** g: -102 pfg: 102 Testing pfg on (-6 3 8): ***different results*** g: 8 pfg: -8 Testing pfg on (-7 2 3): ***different results*** g: 38 pfg: -38 Testing pfg on (5 4 5): ***different results*** g: -40 pfg: 40 ;; Tests on a correct definition of pfg: > (test-pfg) Testing pfg on (10 2 8): same result for g and pfg = 7 Testing pfg on (11 2 8): same result for g and pfg = -102 Testing pfg on (-6 3 8): same result for g and pfg = 8 Testing pfg on (-7 2 3): same result for g and pfg = 38 Testing pfg on (5 4 5): same result for g and pfg = -40
-
-
(7 points) Extend PostFix by adding the following two commands:
-
exp: given a stacki_base i_expt ...(wherei_baseandi_exptare integers), replacesi_baseandi_exptby the result of raisingi_baseto the power ofi_expt(or 0 ifi_exptis negative). -
chs: given a stacki_n i_k ...(wherei_kandi_nare nonnegative integers andi_k<=i_n), replacesi_nandi_kby the value ofi_nchoosei_k. (See the definition of “choose” notation here). If one or both ofi_nandi_kare invalid arguments, displays an error message (sees examples below).
For example:
> (postfix-run '(postfix 0 2 3 exp) '()) 8 > (postfix-run '(postfix 0 3 2 exp) '()) 9 > (postfix-run '(postfix 0 5 3 exp) '()) 125 > (postfix-run '(postfix 0 3 5 exp) '()) 243 > (postfix-run '(postfix 0 0 5 exp) '()) 0 > (postfix-run '(postfix 0 5 0 exp) '()) 1 > (postfix-run '(postfix 0 5 -1 exp) '()) 0 > (postfix-run '(postfix 0 3 -5 exp) '()) 0 > (postfix-run '(postfix 0 6 0 chs) '()) 1 > (postfix-run '(postfix 0 6 1 chs) '()) 6 > (postfix-run '(postfix 0 6 2 chs) '()) 15 > (postfix-run '(postfix 0 6 3 chs) '()) 20 > (postfix-run '(postfix 0 6 4 chs) '()) 15 > (postfix-run '(postfix 0 6 5 chs) '()) 6 > (postfix-run '(postfix 0 6 6 chs) '()) 1 > (postfix-run '(postfix 0 6 7 chs) '()) ERROR: invalid operands for chs (6 7) > (postfix-run '(postfix 0 6 -2 chs) '()) ERROR: invalid operands for chs (6 -2) > (postfix-run '(postfix 0 -6 3 chs) '()) ERROR: invalid operands for chs (-6 3)Notes:
-
Do not modify
postfix-exec-commandfor this part. Instead, just add two bindings to the listpostfix-arithops. -
The Racket built-in
exptfunction is helpful. -
Use a factorial function (we’ve defined many in class!) to implement
chs.
-
-
(4 points) Extend PostFix by adding the following three commands:
leis likelt, but checks “less than or equal to” rather than “less than”geis likegt, but checks “greater than or equal to” rather than “greater than”andexpects two integers at the top of the stack. It replaces them by 0 if either is 0; otherwise it replaces them by 1.
For example:
> (postfix-run '(postfix 0 4 5 le) '()) 1 > (postfix-run '(postfix 0 5 5 le) '()) 1 > (postfix-run '(postfix 0 5 4 le) '()) 0 > (postfix-run '(postfix 0 4 5 ge) '()) 0 > (postfix-run '(postfix 0 4 4 ge) '()) 1 > (postfix-run '(postfix 0 5 4 ge) '()) 1 > (postfix-run '(postfix 0 0 0 and) '()) 0 > (postfix-run '(postfix 0 0 1 and) '()) 0 > (postfix-run '(postfix 0 1 0 and) '()) 0 > (postfix-run '(postfix 0 0 17 and) '()) 0 > (postfix-run '(postfix 0 17 0 and) '()) 0 > (postfix-run '(postfix 0 1 1 and) '()) 1 > (postfix-run '(postfix 0 1 17 and) '()) 1 > (postfix-run '(postfix 0 17 17 and) '()) 1 > (postfix-run '(postfix 0 17 23 and) '()) 1Notes:
-
Do not modify
postfix-exec-commandfor this part. Instead, just add three bindings to the listpostfix-relops. -
The testing function
(test-5c)will test all ofle,ge, andandin the context of the single PostFix programtest-sorted:(define test-sorted '(postfix 3 ; let's call the arguments a, b, and c, from top down 2 nget le ; is a <= b? 3 nget 3 nget ge ; is c >= b? and ; is a <= b and c >= b? )) > (test-5c) ; Uses the test-sorted program in its definition Trying test-sorted on (4 5 6): works as expected; result = 1 Trying test-sorted on (4 5 5): works as expected; result = 1 Trying test-sorted on (4 4 5): works as expected; result = 1 Trying test-sorted on (4 4 4): works as expected; result = 1 Trying test-sorted on (4 6 5): works as expected; result = 0 Trying test-sorted on (5 6 4): works as expected; result = 0 Trying test-sorted on (5 4 6): works as expected; result = 0 Trying test-sorted on (6 5 4): works as expected; result = 0 Trying test-sorted on (6 4 5): works as expected; result = 0 Trying test-sorted on (5 5 4): works as expected; result = 0 Trying test-sorted on (5 4 4): works as expected; result = 0 -
A very common issue students encounter with attempted solutions to
andis that they always return1in the test cases, even though they have associated them with a Racket function that returns0or1. This issue is rooted in not understanding how the Racket function associated with the relop symbol is proceessed. Here are some questions to ask yourself in order to debug this issues should you encounter it:-
Study the functions associated with the other relop symbols. What kind of value do they return? Why?
-
What does the function
postfix-relop->racket-binopdo in the PostFix interpreter implementation?
A lesson here is that you need to truly understand the code you are modifying before modifying it!
-
-
(3 points) Extend PostFix with a
dupcommand that duplicates the top element of the stack (which can be either an integer or executable sequence). For example:(define sos-dup '(postfix 2 dup mul swap dup mul add)) > (postfix-run sos-dup '(3 4)) About to execute commands (dup mul swap dup mul add) on stack (3 4) after executing dup, stack is (3 3 4) after executing mul, stack is (9 4) after executing swap, stack is (4 9) after executing dup, stack is (4 4 9) after executing mul, stack is (16 9) after executing add, stack is (25) 25 (define cmd-dup '(postfix 1 (dup dup mul add swap) dup 3 nget swap exec exec pop)) > (postfix-run cmd-dup '(4)) About to execute commands ((dup dup mul add swap) dup 3 nget swap exec exec pop) on stack (4) after executing (dup dup mul add swap), stack is ((dup dup mul add swap) 4) after executing dup, stack is ((dup dup mul add swap) (dup dup mul add swap) 4) after executing 3, stack is (3 (dup dup mul add swap) (dup dup mul add swap) 4) after executing nget, stack is (4 (dup dup mul add swap) (dup dup mul add swap) 4) after executing swap, stack is ((dup dup mul add swap) 4 (dup dup mul add swap) 4) About to execute commands (dup dup mul add swap) on stack (4 (dup dup mul add swap) 4) after executing dup, stack is (4 4 (dup dup mul add swap) 4) after executing dup, stack is (4 4 4 (dup dup mul add swap) 4) after executing mul, stack is (16 4 (dup dup mul add swap) 4) after executing add, stack is (20 (dup dup mul add swap) 4) after executing swap, stack is ((dup dup mul add swap) 20 4) after executing exec, stack is ((dup dup mul add swap) 20 4) About to execute commands (dup dup mul add swap) on stack (20 4) after executing dup, stack is (20 20 4) after executing dup, stack is (20 20 20 4) after executing mul, stack is (400 20 4) after executing add, stack is (420 4) after executing swap, stack is (4 420) after executing exec, stack is (4 420) after executing pop, stack is (420) 420 > (postfix-run '(postfix 0 dup) '()) ERROR: dup requires a nonempty stack ()Notes:
-
Implement
dupby adding acondclause topostfix-exec-command. -
Test your
dupimplementation using the above test cases. Yourdupimplementation should ensure there is at least one value on the stack, and give an appropriate error message when there isn’t.
-
-
(10 points) In this part you will extend PostFix with a
rotcommand that behaves as follows.-
The top stack value should be a positive integer rotlen that we’ll call the rotation length. Assume there are n values v1, …, vn below rotlen on the stack, where n is greater than or equal to rotlen. Let’s refer to the first rotlen of these n values as the prefix of the n values, and any remaining values as the suffix of the n values.
-
The result of performing the
rotcommand is to ``rotate’’ the prefix by moving v1 to the end of the prefix. That is, the value v1 is moved to index rotlen in the prefix, and each of the values v2 through vrotlen is shifted down index (i.e., moved one position to the left) so that they now occupy the indices 1 through rotlen-1. So afterrotis performed, the elements of the prefix are v2 … vrotlen v1. For example, if rotlen is 2, thenrotacts likeswap, and if rotlen is 1, thenrotleaves the stack unchanged. -
The values in the suffix are unchanged by
rot. -
When rotlen is 0, a negative integer, or a noninteger, the
rotcommand signals an error.
Here are examples involving
rot:(define rot-test '(postfix 6 4 rot 3 rot 2 rot)) > (postfix-run rot-test '(8 7 6 5 9 10)) About to execute commands (4 rot 3 rot 2 rot) on stack (8 7 6 5 9 10) after executing 4, stack is (4 8 7 6 5 9 10) after executing rot, stack is (7 6 5 8 9 10) after executing 3, stack is (3 7 6 5 8 9 10) after executing rot, stack is (6 5 7 8 9 10) after executing 2, stack is (2 6 5 7 8 9 10) after executing rot, stack is (5 6 7 8 9 10) 5 > (postfix-run '(postfix 3 (mul add) rot) '(5 6 7)) About to execute commands ((mul add) rot) on stack (5 6 7) after executing (mul add), stack is ((mul add) 5 6 7) ERROR: rot length must be a positive integer but is (mul add) > (postfix-run '(postfix 3 -1 rot) '(5 6 7)) About to execute commands (-1 rot) on stack (5 6 7) after executing -1, stack is (-1 5 6 7) ERROR: rot length must be a positive integer but is -1 > (postfix-run '(postfix 3 4 rot) '(5 6 7)) About to execute commands (4 rot) on stack (5 6 7) after executing 4, stack is (4 5 6 7) ERROR: not enough stack values for rot (4 5 6 7) > (postfix-run '(postfix 0 rot) '()) About to execute commands (rot) on stack () ERROR: rot requires a nonempty stack but is ()Notes:
-
Implement
rotby adding acondclause topostfix-exec-command. -
Racket supplies a
list-tailfunction that is very helpful for implementingrot:> (list-tail '(10 20 30 40 50) 0) '(10 20 30 40 50) > (list-tail '(10 20 30 40 50) 1) '(20 30 40 50) > (list-tail '(10 20 30 40 50) 2) '(30 40 50) > (list-tail '(10 20 30 40 50) 3) '(40 50) > (list-tail '(10 20 30 40 50) 4) '(50) > (list-tail '(10 20 30 40 50) 5) '()Racket does not provide a similar
list-headfunction, but I have provided it in theps6-postfix-starter.rktfile. It works this way:> (list-head '(10 20 30 40 50) 0) '() > (list-head '(10 20 30 40 50) 1) '(10) > (list-head '(10 20 30 40 50) 2) '(10 20) > (list-head '(10 20 30 40 50) 3) '(10 20 30) > (list-head '(10 20 30 40 50) 4) '(10 20 30 40) > (list-head '(10 20 30 40 50) 5) '(10 20 30 40 50) -
Test your
rotimplementation using the above test cases. Yourrotimplementation should give appropriate error messages in various situations, like those in the test cases.
-
4. Static Stack Depth in the Intex-to-PostFix Compiler (21 points)
The intexToPostFix function discussed at the beginning of Thu Dec 10 Lec 32
automatically translates an Intex program to a PostFix program that has the same meaning.
(See the fleshed out version of `intexToPostFix`
in slide 5 of the
Lec 31 Intex solution slides
or the file ~/cs251/sml/intex/IntexToPostFix.sml in your csenv application).
The challenging part of this translation is determining the correct index to use for an Nget command when translating an Arg node in an Intext AST.
The key to solving this technical problem is to provide the expToCmds helper function with a depth argument that statically tracks the number of values that have been pushed on the PostFix stack above the argument values at any point of the computation.
The purpose of this problem is for you to study this idea in the context of a particular Intex program so that you better understand it.
-
(3 points) Draw the abstract syntax tree for the following Intex program, which we shall call
P_Intex.(intex 4 (div (add ($ 1) (mul ($ 2) (sub ($ 3) ($ 4)))) (rem (sub (mul ($ 4) ($ 3)) ($ 2)) ($ 1))))For drawing the Intex AST, use the conventions illustrated in slides 3 and 4 of the the Lec 31 Intex slides.
You may draw the tree by hand or use a drawing program, whichever is easier for you. This will be a wide diagram, so you’ll want to draw it in landscape mode rather than portrait mode. To save space, do not label the edges (i.e., no
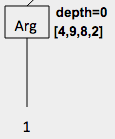
numargs,body,rator,rand1,rand2,index, orvaluelabels should be used).Since you will be annotating this tree with extra information in parts b and d, leave enough room to add some annotations to the right of each node. Here is an example of an annotated node.
-
(4 points) In your AST for
P_Intexfrom part a, annotate each expression node with thedepthassociated with that node when it is encountered by theexpToCmdsfunction within theintexToPostFixfunction. As shown above, you should write depth=d to the right of each expression node, where d is the depth of the node. -
(6 points) Write down the PostFix program that is the result of translating the Intex program
P_Intexfrom part a using theintexToPostFixfunction. We shall call this programP_PostFix. (You should do this translation by hand, not by running the function in SML.) Important: You translated PostFix code must be exactly the code that would be generated by theintexToPostFixfunction, not just a PostFix program that happens to have the same behavior. Why? Because the purpose of this problem is to understand how theintexToPostFixfunction (and, in particular, itsdepthargument) work.Use comments to explain the commands in the translated program. Here is an example of commenting the PostFix code that was generated by translating the Intex program example
(intex 4 (* (- ($ 1) ($ 2)) (/ ($ 3) ($ 4))))in Lec 31 (see slide 4 of the Lec 31 Intex solution slides).(postfix 4 1 nget ; $1 3 nget ; $2, know that $1 on stack sub ; (- $1 $2) 4 nget ; $3, know that (- $1 $2) on stack 6 nget ; $4, know that $3 and (- $1 $2) on stack div ; (/ $3 $4) mul ; (* (- $1 $2) (/ $3 $4)) -
(8 points) Consider running
P_Intexon the four arguments[4, 9, 8, 2]. In your AST forP_Intexfrom part a, annotate each expression node with the list of integers that corresponds to the PostFix stack that will be encountered just before the last command translated for that node byexpToCmdsis executed in the PostFix programP_PostFix. As shown above, you should write the stack as an SML-style list to the right of the node below the depth.For example, below is the result of annotating the Intex AST for
(intex 4 (* (- ($ 1) ($ 2)) (/ ($ 3) ($ 4))))withdepthinformation and the stack before executing each node when the program is given the arguments[15, 8, 30, 5].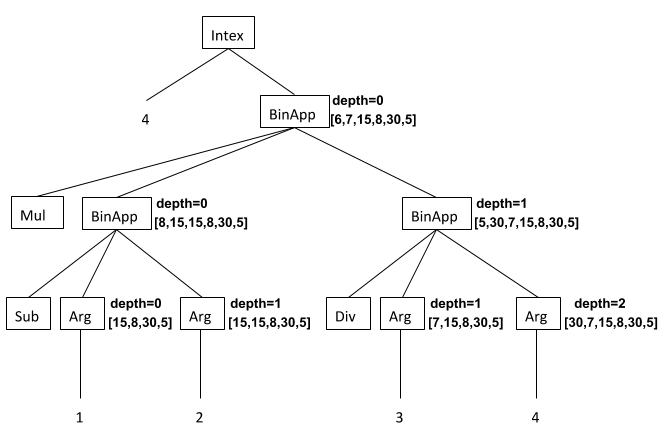
Some things to observe:
- At each
Argnode in the program, the PostFix stack index of that argument in the stack annotating the node is theArgindex value plus thedepthannotating the node. In particular:- The
Argnode with index 1 has depth 0, and so translates to1 nget. - The
Argnode with index 2 has depth 1, and so translates to3 nget. - The
Argnode with index 3 has depth 1, and so translates to4 nget. - The
Argnode with index 4 has depth 2, and so translates to6 nget.
- The
- Only Intex expression nodes (
BinAppandArgnodes in this example) have annotations. ThebinopnodesSub,Div, andMulare not annotated, nor are theArgindex values or the top-levelIntexprogram node. - Here's an explanation of the stack annotations on the Intex AST nodes in the example:
- Execution of the translated program begins with the translation of the
Argnode with index 1 to1 nget. Before these commands are executed, the stack just contains the four argument values:[15, 8, 30, 5]. The result of executing the PostFix code for this node is[15, 15, 8, 30, 5]. The fact that the value of the left operand ofSubhas been pushed on the stack causes the depth to increment from 0 to 1 for the right operand. - The translated program executes the translation of the
Argnode with index 2, which is3 nget. Before these commands are executed, the stack contains the result of executing the PostFix code in Step 1, so the stack is[15, 15, 8, 30, 5]. The result of executing the PostFix code for this node is[8, 15, 15, 8, 30, 5]. - The translated program performs the
subcommand translated for the end of the code for theSub BinAppnode. Before the subtraction is performed, the stack is the result of executing the PostFix code in Step 2, so the stack is[8, 15, 15, 8, 30, 5]. The result of executing the PostFix code for this node is[7, 15, 8, 30, 5]. Since two stack values were popped but one was pushed when executingsub. So the depth for the next step (the divisionBinApp) is still 1. - The translated program executes the translation of the
Argnode with index 3, which is4 nget. Before these commands are executed, the stack contains the result of executing the PostFix code in Step 3, so the stack is[7, 15, 8, 30, 5]. The result of executing the PostFix code for this node is[30, 7, 15, 8, 30, 5]. Pushing the left operand of theDiv BinAppincrements the depth from 1 to 2 for its right operand. - The translated program executes the translation of the
Argnode with index 4, which is6 nget. Before these commands are executed, the stack contains the result of executing the PostFix code in Step 4, so the stack is[30, 7, 15, 8, 30, 5]. The result of executing the PostFix code for this node is[5, 30, 7, 15, 8, 30, 5]. - The translated program performs the
divcommand translated for the end of the code for theDiv BinAppnode. Before the divistion is performed, the stack is the result of executing the PostFix code in Step 5, so the stack is[5, 30, 7, 15, 8, 30, 5]. The result of executing the PostFix code for this node is[6, 7, 15, 8, 30, 5]. - The translated program performs the
mulcommand translated for the end of the code for theMul BinAppnode. Before the multiplication is performed, the stack is the result of executing the PostFix code in Step 6, so the stack is[6, 7, 15, 8, 30, 5]. The result of executing the PostFix code for this node is[42, 15, 8, 30, 5]. This stack is not shown in the annotated tree, but is the final stack for the program (which returns the result value 42).
- Execution of the translated program begins with the translation of the
- At each
</ul>
Problem 5. Extending Intex with a Conditional Expression (32 points)
Starting this Problem
This problem involves files in the ~/cs251/sml/ps6 directory in your csenv Virtual Machine.
To create this directory, execute this Linux commands in a shell on your csenv appliance:
cd ~/cs251/sml
git pull origin masterIf you encounter any issues when executing these commands, you can troubleshoot by following these git instructions. If these instructions don’t help, please contact Lyn.
Begin this problem by renaming 2 files::
-
Rename the starter file
Condex.smlin~/cs251/sml/ps6toyourAccountName-Condex.sml. -
Rename the starter file
CondexToPostFix.smlin~/cs251/sml/ps6toyourAccountName-CondexToPostFix.sml. -
In your renamed file
yourAccountName-CondexToPostFix.sml, edit this line near the top of the fileuse "Condex.sml"; (* semi-colon required! *)to be
use "yourAccountName-Condex.sml"; (* semi-colon required! *)
It is important to rename these files at the very beginning, because renaming the files protects you from git issues if I need to modify the starter files.
REMINDER: ALWAYS MAKE A BACKUP OF YOUR .sml FILES AT THE END OF EACH DAY TO AVOID POTENTIAL LOSS OF WORK.
The Condex Language
Both tasks in this problem involve the Condex language, which is an extension to Intex. As in Intex, all values in Condex are integers. But Condex includes the follow extra features:
-
Condex includes the relational operators
<,=, and>. Since all Condex values are integers, these operators return 1 in the true case and 0 in the false case. This is similar to relational operators in PostFix. -
Condex includes the conditional expression
(ifnz E_test E_then E_else)whereifnzstands forif-non-zeroand is pronouncediffenz. The meaning of the ifnz expression is as follows:First, the
E_testexpression is evaluated to an integer valueV_test.-
If
V_testis non-zero, then theE_thenexpression is evaluated, and its value is returned as the value of theifnzexpression; -
If
V_testis zero, then theE_elseexpression is evaluated, and its value is returned as the value of theifnzexpression; -
If an error is encountered during any of these evaluations, evaluating the
ifnzexpression gives the same error.
As with Racket’s
ifexpresssion, Condex’sifnzevaluates at most two subexpressions.E_testis always evaluated, and if that evaluation does not give an error, exactly one ofE_thenorE_elseis evaluated. -
Condex programs are like Intex programs, except they begin with the
symbol condex rather than intex. Your ~/cs251/sml/ps6 directory
contains several sample Condex programs (with extension .cdx) that
we will now discuss:
-
The program in the file
abs.cdxcalculates the absolute value of its single argument:(condex 1 (ifnz (< $1 0) (- 0 $1) $1)) -
The program
simpleIf.cdxusesifnzin a simple conditional test:(condex 2 (ifnz (< $1 $2) (+ $1 $2) (* $1 $2)))For example, running this program on the arguments 3 and 4 should return 7, but calling it on 4 and 3 should return 12.
-
The program
min3.cdxreturns the smallest of its three arguments:(condex 3 (ifnz (< $1 $2) (ifnz (< $1 $3) $1 $3) (ifnz (< $2 $3) $2 $3)))For example, running this program on three arguments 4, 5, and 6 (in any order) should return 4.
-
The program
sumRelations.cdxdoesn’t contain any occurrences ofifnz, but uses the fact that relational operations return 0 or 1 to sum the value of three such operations:(condex 4 (+ (< $1 $2) (+ (= $1 $3) (> $1 $4))))For example, running this program on the four arguments 5, 6, 5, 4 returns 3, because
(< 5 6),(= 5 5), and(> 5 4)all return 1. But running it on the four arguments 5, 3, 7, 4 returns 1, because(< 5 3)and(= 5 7)return 0 and only(> 5 4)returns 1. -
In a Lec 30 Jamboard exercise, we considered translating the following Racket function to PostFix because it illustrated the importance of evaluating only one of the then and else branches (since the branch that’s not supposed to be taken could encounter and error).
(define (test a b c) (if (> a b) (/ b c) (remainder b a)))The
lec30Test.cdxprogram below is how the above Racket program would be expressed in Condex:(condex 3 (ifnz (> $1 $2) (/ $2 $3) (% $2 $1)))Using the examples from Lec 30:
-
running this program on the arguments 0, -8, and 2 should return -4 from the then branch (but not execute the else branch expression
(% -8 0), which would encounter a remainder-by-zero error). -
running this program on the arguments 5, 8, and 0 should return 3 from the else branch (but not execute the then branch expression
(/ 8 0), which would encounter a divide-by-zero error).
However, running it on the arguments 2, 1, 0 would encounter a divide-by-zero error in the then branch, and the arguments 0, 1, 2 would enounter a remainder-by-zero error in the else branch.
This
lec30Test.cdxprogram will be a particularly relevant example when we consider compiling Condex to PostFix in Part b of this problem. -
-
Problem 3a of this PS6, considers another Racket function,
g, for translation into PostFix(define (g a b c) (- c (if (= 0 (remainder a 2)) (quotient b (- a c)) (* (+ b c) a))))The Condex program prob3a-g.cdx expresses this function in Condex:
(condex 3 (- $3 (ifnz (= 0 (% $1 2)) (/ $2 (- $1 $3)) (* (+ $2 $3) $1))))Some relevant test cases from Problem 3a are that the three arguments 10, 2, and 8 yield the result 7, and the argments 5, 3, 5 yield the result -40. (See the comments in the file for more test cases.
-
As a final example, the
nestedIfs.cdxprogram is a complex program that usesifnzexpressions as the test, then, and else subexpressions of an outerifnzexpression.(condex 3 (ifnz (ifnz (< $1 $2) (< $1 $3) (> $1 $3)) (ifnz (= $2 $3) (* $2 $2) (% $2 $3)) (ifnz (> $2 $3) (/ $2 $3) (- $3 $2))))See the comments of this file for several test cases.
In the rest of this problem, your goal will be to flesh out (1) the skeleton a Condex interpreter implemented in SML and (2) the skeleton of Condex-to-Postfix compiler implemented in SML. The above programs will be used in test cases that your programs behave as expected.
SML Sum-of-product and S-expression Syntax for Condex
In the ps6 directory on your csenv appliance, your file
yourAccountName-Condex.sml contains the definition of the
SML representation for Condex syntax. This syntax is
is very similar to that for the Intex interpreter
we studied in class (and which can be found in ~/cs251/sml/Intex.sml).
Here are the datatypes and helper functions used to represent Condex program trees:
datatype pgm = Condex of int * exp
and exp = Int of int
| Arg of int
| ArithApp of arithop * exp * exp (* Named changed from Intex's BinApp *)
| RelApp of relop * exp * exp (* New in Condex *)
| Ifnz of exp * exp * exp (* New in Condex: E_test, E_then, E_else *)
and arithop = Add | Sub | Mul | Div | Rem (* Named changed from Intex's binop *)
and relop = Lt | Eq | Gt (* <, =, > *)
(* Named changed from Intex interpreter's binopToFun *)
and arithopToFun Add = op+
| arithopToFun Mul = op*
| arithopToFun Sub = op-
| arithopToFun Div = (fn(x,y) => x div y)
| arithopToFun Rem = (fn(x,y) => x mod y)
(* New in Condex interpreter *)
and relopToFun Lt = op<
| relopToFun Eq = (fn(a,b) => a = b)
| relopToFun Gt = op>Here are some differences from Intex worth noting:
-
Programs are constructed via the
Condex(notIntex) constructor; -
IntandArgare unchanged fromIntex. -
Intex’s
BinAppconstructor has been renamed toArithApp, and Intex’sbinopoperators have been renamed toarithop. -
The
RelAppconstructor and thereloptype are new in Condex; they represent relational operations (<,=,>). -
The
Ifnzconstructor is new in Condex and represents theifnzconstruct. -
Intex’s
binopToFunhelper function (which defines the meaning of thearithopoperators) has been renamed toarithopToFun. -
The new helper function
relopToFundefines the meaning of therelopoperators.
Additionally, yourAccountName-Condex.sml contains functions for
parsing s-expression strings into, and unparsing s-epxpression strings from,
the sum-of-product notation. For example:
- val ifnzExp = stringToExp "(ifnz (< $1 6) (+ $1 3) (* $2 $2))";
val ifnzExp =
Ifnz
(RelApp (Lt,Arg 1,Int 6),ArithApp (Add,Arg 1,Int 3),
ArithApp (Mul,Arg 2,Arg 2)) : exp
- expToString ifnzExp;
val it = "(ifnz (< ($ 1) 6) (+ ($ 1) 3) ( * ($ 2) ($ 2)))" : string
- val simpleIfPgm = stringToPgm "(condex 2 (ifnz (< $1 $2) (+ $1 $2) (* $1 $2)))";
val simpleIfPgm =
Condex
(2,
Ifnz
(RelApp (Lt,Arg 1,Arg 2),ArithApp (Add,Arg 1,Arg 2),
ArithApp (Mul,Arg 1,Arg 2))) : pgm
- pgmToString simpleIfPgm;
val it = "(condex 2 (ifnz (< ($ 1) ($ 2)) (+ ($ 1) ($ 2)) ( * ($ 1) ($ 2))))"
: string(The above examples assume you have opened the Condex structure
via open Condex. Also, full sum-of-product trees are printed only after executing
- Control.Print.printDepth := 100;)
Your Tasks
-
(10 points)
yourAccountName-Condex.smlalso contains the skeleton of a Condex intepreterevalfunction similar to the one defined for Intex. All you need to do is to replace the stubs for theRelAppandIfnzclauses ofevalso that they return the correct integer result as specified by the semantics of Condex.Notes:
-
You may define helper functions(s) if you want.
-
The easiest way to test your
evalfunction is to evaluate the function calltestInterp(), which will run the evaluator on numerous test cases involving the.cdxprogram files described above.-
If you see a result like
"Passed all 39 test cases", it means yourevalfunction has passed all the test cases. (You can scroll up to see the details.) -
If you see a result that begins with something like
"Failed 4 of 39 test cases ...", you should scroll up searching for the string***ERROR, which will give details on the test program and arguments causing the failure, along with the expected and actual results.
-
-
The easiest way to test your own examples is to launch a Condex Read/Eval/Print loop via
repl(). For example:- repl(); condex> (< 3 4) 1 condex> (> 3 4) 0 condex> (ifnz (< 1 2) (+ 3 4) ( * 5 6)) 7 condex> (ifnz (> 1 2) (+ 3 4) ( * 5 6)) 30 condex> (#args 8 5 9) condex> (ifnz (< $1 $2) (+ $2 $3) (- $2 $3)) ~4 condex> (#run (condex 3 (ifnz (< $1 $2) $2 $3)) 4 5 6) 5 condex> (#run (condex 3 (ifnz (< $1 $2) $2 $3)) 4 3 6) 6 condex> (#run min3.cdx 42 17 57) 17 condex> (#quit) Moriturus te saluto! val it = () : unit -
You can call
testInterp()andrepl()without theCondex.qualifier, but if you want to access values from the Condex module, you will either need to (1) explicitly qualify them withCondex.or (2) open theCondexstructure viaopen Condex.
-
-
(22 points) The file
yourAccountName-CondexToPostFix.smlcontains the skeleton of a Condex to Postfix compiler that is very similar to the one we studied at the beginning of Lec 32 for Intex.
The core function in the compiler isexpToCmds, which has the typeval expToCmds: Condex.exp -> int -> PostFix.cmd list *)It takes a Condex expression and a depth argument that tracks the number of values that have been pushed above the program arguments on the stack when
expToCmdsis called (this is used as an offset for the index when compiling a program argument).expToCmdsreturns a list of PostFix commands.The
Int,Arg, andArithAppcases ofexpToCmdsare already correctly implemented. What you need to do is flesh out theRelAppandIfnzcases.-
(12 points) The
lec30Test.cdxprogram is the expression in Condex of the Racket program you translated by hand into PostFix in a Lec 30 Jamboard exercise.(condex 3 (ifnz (> $1 $2) (/ $2 $3) (% $2 $1)))It is imperative that you understand how this Condex program should be translated into PostFix before you attempt to flesh out the
RelAppandIfnzcases ofexpToCmdsin the next subpart.For this part, write the exact PostFix program that should be generated by the the
condexToPosFixfunction when given this Condex program. You should annotate the commands with explanatory comments as described in Problem 4c.You should also show the sequence of all intermediate stacks for executing your PostFix program on the argument lists from the following examples:
condex> (#run lec30Test.cdx 6 17 0) 5 condex> (#run lec30Test.cdx 0 -18 3) ~6Of course, your PostFix program should give the same result as the Condex interpreter.
-
(10 points) Flesh out the
RelAppandIfnzclauses ofexpToCmdsso that they implement a generalized version of your strategy from thelec30Test.cdxexample.Notes:
-
In order to load the file
yourAccountName-CondexToPostFix.sml, you will need to edit this line near the top of the fileuse "Condex.sml"; (* semi-colon required! *)to be
use "yourAccountName-Condex.sml"; (* semi-colon required! *) -
You should explicitly use qualified names beginning with
Condex.andPostFix.to distinguish function values from these two structures. -
To test your
expToCmds, evaluate the function calltestComp(). This will do the following for the Condex.cdxprograms in theps6directory:-
Compile the Condex program into a PostFix program using the
condexToPostFixfunction, which depends on your changes to theexpToCmdsfunction. -
For various arguments lists, run both the original Condex program (using your Condex intepreter from Part a) and the compiled PostFix program (using the SML PostFix interpreter we studied in class) on the argument lists and test that the outputs are the same.
-
If you see a result like
"Passed all 37 test cases", it means your compiler has passed all the test cases. (You can scroll up to see the details.) -
If you see a result that begins with something like
"Failed 4 of 37 test cases ...", you should scroll up searching for the string***ERROR, which will give details on the test program and arguments causing the failure, along with the different results from the Condex and PostFix interpreters. The testing output also displays the PostFix program that results from the compilation process for each Condex program. You should carefully study the PostFix programs output from the compiler as part of debugging.
-
-
-
Extra Credit: PostFix Iterations (15 points)
This problem is optional. You should only attempt it after completing all the other problems.
-
(5 points) Study and test the following
mysteryPostFix program of one argument, which is provided near the end ofps6-postfix-starter.rkt. Describe the function that it calculates on its one argument, and give a brief, high-level description of how it calculates that function.;; What function does this compute? (define mystery '(postfix 1 1 (swap dup 0 eq (swap) (swap 2 nget mul swap 1 sub swap 3 vget exec) sel exec) 3 rot 3 vget exec))Note:
vgetis a command that is likenget, except that it can return any value (including an executable sequence), not just an integer. It has been included in yourps6-postfix-starter.rktfile for use in this extra credit problem. -
(10 points) Write a PostFix program that takes a single argument (assumed to be a nonnegative integer n) and iteratively calculates the nth Fibonacci number. Full credit will be given only if you use constant stack space; i.e., calculating the Fibonacci of a larger number should not end up with a final stack that has more elements than for a smaller number.