PS1: Evaluating Languages
-
Due: 11:59pm Thu 14 September
- Relevant reading:
- Syllabus
- Racket (through the section Expressions, Values, Bindings, and Environments)
- Optional: Why Undergraduates Should Learn the Principles of Programming Languages, 2011.
- Tools:
-
Overview: The purpose of this assignment is to get you thinking about the dimensions of programming languages and about evaluating and comparing programming languages. It also has exercises on Racket and big-step vs. small-step semantics.
-
Collaboration: All parts of this assignment fall under the standard Gilligan’s Island Rule collaboration policy. That is, you may discuss the problems and strategies for solving them with classmates and other, but all coding and written solutions must be your own individual work.
-
Submission:
Your CS251 work this semester will be submitted via a combination of submitting written work via Google Docs and submitting code files via a drop folder on cs.wellesley.edu. Here’s how to submit this pset.
-
Begin by creating a Google Drive folder named yourFullName CS251 Fall 2017 Folder (e.g.
Georgia Dome CS251 Fall 2017 Folder) that you share with me and Jane Abernathy with editing privileges. During the course, you will create many Google Docs in this folder, and by default they will inherit these permissions. -
Within the folder from Step 1, create a Google Doc named yourFullName CS251 PS1 (e.g.,
Georgia Dome CS251 PS1). At the top of this file, put a header like this:CS251 PS1 Wendy Wellesley <Put submission date here> <Put time estimates for individual problem parts here>As you work on problems, please keep track of the time you spend and report the time spend on problem parts in the header. This feedback is critical for helping me design the psets to take a reasonable amount of time.
Going forward during the semester, you should put this sort of header at the top of every pset.
-
Now create a file folder on your computer named yourCSAccountName_ps1 (e.g.,
gdome_ps1). Below you will be asked to populate this file folder with various files on the assignment that you will submit (in the final step) to a drop folder oncs.wellesley.edu. -
Submit your work as described below.
-
For Problem 1 (Concrete Syntax):
-
Put your
updateScore.pyandupdateScore.jsfiles in youryourCSAccountName_ps1folder. -
Copy the contents of these files into a Problem 1 section of your PS1 Google Doc. Format your code here (and in all subsequent probblems) using a fixed-width font, like Courier New or Consolas. Make sure that code formatting is correct and easy to read. In particular, Python code must be indented properly. You can use a small font size if that helps.
-
-
For Problem 2 (Python vs. Java):
-
For parts (a) and (c), include in the Problem 2 section of your PS1 Google Doc your written answer to these parts.
-
Put your
printNames.javafile and a copy of thenames.txtfile in youryourCSAccountName_ps1folder. -
For part (b), copy the contents of
printNames.javainto the Problem 2 section of your PS1 Google Doc. Make sure that the code formatting is easy to read.
-
-
For Problem 3 (Revenge of the Nerds), include your writeup in a Problem 3 section of your PS1 Google Doc.
-
For Problem 4 (Racket Evaluation), in a Problem 4 section of your PS1 Google Doc, write one binding (or error) per line.
-
For Problem 5 (Big-step and Small-Step Semantics), in a Problem 5 section of your PS1 Google Doc:
-
For part (a), include your big-step derivation.
-
If you choose conclusion-above-subderivations format, you can use Google Docs bulleting mechanism to format the lines, but code should still be in fixed-width font (Courier New or Consolas).
- If you choose conclusion-below-subderivations format, you should format the whole derivation in a fixed-width font.
- Be sure to label every horizonal line with the name of the rule applied.
-
-
For part (b), include your small-step derivation.
-
Use a fixed-width font for all code.
-
Be sure to mark the redex in a line with curly braces
-
Be sure to label the result of every reduction step wit the name of the rule applied to get that result.
-
-
-
-
Copy your final
yourCSAccountName_ps1folder to yourps01cs251 drop folder on cs.wellesley.edu. This drop folder will be in acs251/drop/ps01subfolder of your account.
-
1. Concrete Syntax (15 points)
This problem explores how the same program can be written with different concrete syntax in different languages.
Consider the following App Inventor program, which consists of two global variable declarations and the declaration of an updateScore procedure. (This program is incomplete, since updateScore is never called.)
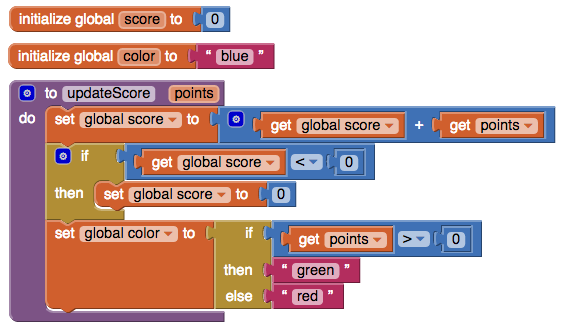
Create two files, updateScore.py and updateScore.js, that contain, respectively, (1) Python and (2) JavaScript versions of this App Inventor program. These files should also include test cases that show the programs work as expected.
Notes:
-
If you don’t know or can’t remember details of Python or JavaScript syntax, look it up on the Web!
-
The App Inventor example includes two global variable declarations (
scoreandcolor), a local procedure parameter declaration (points), variable references (getters) for all of these, and variable assignments (setters) for the global variables. In one of your programs, you will need an extra declaration to distinguish global from local variables. Why? (You don’t need to answer this question in your solution, but should think about it.) -
App Inventor includes both conditional statement blocks (the two left blocks below) and conditional expression blocks (the rightmost block below). Make sure you understand the difference between these and translate them appropriately.

In general, a statement is a program phrase that performs an action while an expression is a program phrase that returns a value. In App Inventor, statements compose vertically to emphasize that their actions are performed sequentially from top to bottom, while expressions have plugs on their left side that denote the value returned by the expression. This value is used by the block whose socket the plug is connected to.
Both Python and JavaScript have different syntax for conditional statements vs. conditional expressions. In your programs, you should use the appropriate syntax for each one. (If you don’t know it, look it up!) In particular, do not use the conditional statement syntax to translate App Inventor’s conditional expression block!
BTW #1, App Inventor also has top-level declarations (blocks that introduce top-level named entities, like procedures and global variables). These are blocks that do not have any plugs or sockets and so cannot be connected to other blocks.
BTW #2, Racket only has declarations and expressions; it does not have statements. So Racket’s
ifis a condtional expression and not a conditional statement. What’s it like to program in a language without statements? You’ll find out! -
What App Inventor calls a “procedure” is called a “function” in Python and JavaScript. The term “function” often implies that callers for the entity can return a value (i.e., function calls are expressions), whereas “procedure” often implies that callers for the entity perform an action but do not return a value (i.e., procedure calls are statements). But the usage is rather inconsistent between languages.
-
You must test your
updateScorefunctions to verify that they work correctly. E.g., you can use Canopy or some other Python intepreter to testupdateScore.pyand a browser JavaScript interpreter to testupdateScore.js.
2. Python vs. Java (40 points)
All general-purpose programming languages are Turing-complete, which means that they all can be used to define the same set of computable functions. However, PLs differ in their “expressiveness”, an informal notion that attempts to capture how easy it is to write a program in one language vs. another.
This problem explores the notion of expressiveness by asking you (1) to understand a give Python program (2) to translate that program into Java and (3) to compare the resulting Java program to the original Python program.
a. Understanding a Python Program (10 points)
Below is the contents of a Python program printNames.py.
import sys
def printNames(namesFile, numEntries):
with open (namesFile, 'r') as inFile: # open namesFile for reading
nameDict = {} # create an empty dictionary
for line in inFile.readlines():
# associate each first name with a list of last names
first, last = line.split()
if first not in nameDict:
nameDict[first] = [last]
else:
nameDict[first].append(last)
# Below, an "item" is a pair of (1) a first name and (2) an associated list of last names
sortedItems = sorted(nameDict.items(),
# How does the following key function sort the items?
key=lambda (first,lasts): totalLength(lasts),
reverse=True) # Sort items in descending rather than ascending order by key.
for (fst,lastList) in sortedItems[:max(0,numEntries)]: # what is max doing here?
sortedLasts = sorted(lastList,
# How does the following key function sort the last names in lastList?
# Note that the key returns a *pair* of string length and string. Why?
key=lambda s: (len(s), s))
# Use "list comprehension" notation (in brackets) to create a list of numbered lines.
numberedLines = [str(i+1) + '. ' + s for i,s in enumerate(sortedLasts)]
print '--------\n' + fst + ' (' + str(totalLength(sortedLasts)) + '):\n' \
+ '\n'.join(numberedLines)
def totalLength(strings):
return sum([len(s) for s in strings])
if __name__ == "__main__":
if len(sys.argv) != 3:
print "Usage: python findNames.py <namesFile> <numEntries>"
else:
# All kinds of errors can occur here, but don't worry about exception handling
printNames(sys.argv[1], int(sys.argv[2]))Here is a sample input file names.txt on which to run printNames.py. (This file was generated using http://homepage.net/name_generator/.)
Here’s an example of how to run the program from the command line in a terminal on a Mac:
python printNames.py names.txt 10Here’s how you can run it from the Canopy interaction window:
%run "printNames.py" names.txt 10(Both of the above examples assume you are “connected” to a directory containing the files printNames.py and names.txt.)
After carefully studying the program and examining its output when run on the sample input file, describe exactly what the program does in terms of its input/output behavior. Your description must be precise enough that someone else could implement the program from scratch based on your description without seeing the code for printNames.py.
Some notes to keep in mind:
-
Writing concise but informative input/output specifications is hard, and you shouldn’t be surprised if you had difficulty doing it and it requires many passes. But this is a skill that you need to eventually become good at, and you need practice to get better at it.
-
Do not give a line-by-line or step-by-step explanation of Python program. You are asked to describe what output is generated for a given input, not how that output is generated. In particular:
-
Carefully describe the expected format of the command line arguments and the input file specified by one of the arguments.
-
Carefully describe the printed output, down to the level of what characters should be on particular lines. Remember, based on your specification, someone else should be able to reproduce the exact output of the Python program without seeing that program!
-
There are many details of the Python program that do not affect the output and so should not be mentioned. For example, the in the first phase of the program, last names are added to the list of last names in the order they’re encountered. But the printed output does not depend on this order, so it should not be mentioned.
-
In your description it will be helpful to refer to various kinds of data items and collections. Rather than referring to particular data structure names (like list, array, dictionary, or hashmap), it’s better for a spec to use terms that are more generic (such as sequence, set, or key-value mapping), so that unnecessary details of the data structure do not influence the reader. For example, when a list is used to represent a set (an unordered collection without duplicates), the name “set” should be used rather than “list”. Terms like “item”, “entry”, or “key-value pair” are reasonable, but you need to carefully define what these mean in your particular specification. E.g., in one program, an “entry” might refer to a triple of (1) a string that is the student’s full name, (2) an integer representing their graduation year and (3) a set of strings that are the names of the courses they have taken.
-
Concrete examples are sometimes helpful to explain complex specifications, but you should never use an example to replace a part of the specification. The specification should still be complete without any examples.
-
-
If you’re not sure whether you’ve provided sufficient detail, give your specification to someone else and ask what questions they have about the program’s behavior.
-
It is important to explicitly say how certain details are handled. For example:
-
When items are sorted, what determines the ordering of the items?
-
What happens when there’s a “tie” between sorted items?
-
What does the program do if the same last name appears more than once for a given first name?
-
What if numEntries is bigger than number of first names?
-
What if numEntries is negative?
-
-
It is also important to explicitly state unspecified behavior in the program. For example, in what cases is the Python program ambiguous about specifying the relative ordering of elements?
-
In this problem, you need not specify errors/exceptions for unexpected inputs. Instead, explicitly state assumptions about the inputs for which the program will work correctly.
b. Translating the Python Program to Java (20 points):
In this part, you will flesh out the following Java skeleton program printNames.java (get it here) so that it has the same input/output behavior as printNames.py on “expected” command line arguments.
import java.io.*; // Needed to use File and FileNotFoundException classes
import java.util.*; // Needed for classes like Scanner, ArrayList, HashMap, Collection, etc.
/**
* A Java class with a static doPrintNames method that acts like the printNames
* function in printNames.py.
*
* Invoking the main method of this class on command line arguments behaves like
* invoking printNames.py on command line arguments.
*
* This class does *not* have have any instance variales or methods or
* (nontrivial) constructor methods. It is not expected that instances of this
* class will be created. Rather, this class is just a respository for
* the doPrintNames static method corresponding to the Python printNames function.
*
*/
public class printNames {
/**
* This Java static method should have the same behavior as the Python printNames function
* in printNames.py.
*
* @param filename The relative pathname of a file of first and last names
* @param numEntries A positive integer indicating the number of entries to be displayed
*
*/
public static void doPrintNames(String filename, int numEntries) throws FileNotFoundException {
Scanner reader = new Scanner(new File(filename)); // reader is object that reads lines of file
HashMap<String, ArrayList<String>> nameDict = new HashMap<String, ArrayList<String>>();
// nameDict is dictionary associating first name with list of all last names it appears
// with in file (including duplicates)
while (reader.hasNextLine()) {
String line = reader.nextLine();
String [] names = line.split("\\s+"); // split on whitespace
String first = names[0];
String last = names[1];
ArrayList<String> lastNameList;
if (!nameDict.containsKey(first)) {
// Create empty lastNameList and associated it with first name key
lastNameList = new ArrayList<String>();
nameDict.put(first,lastNameList);
} else {
// Find existing lastNameList associated with first name key
lastNameList = nameDict.get(first);
}
// Add last name to lastNameList associated with first name key
lastNameList.add(last);
}
// Convert the set of entries into an ArrayList so that we can use Collections.sort on it.
List<Map.Entry<String,ArrayList<String>>> entriesList
= new ArrayList<Map.Entry<String,ArrayList<String>>>(nameDict.entrySet());
// Complete this program skeleton so that it behaves like printNames.py
// Feel free to define any extra methods or classes that you find useful.
}
public static void main (String[] args) {
if (args.length != 2) {
System.out.println("Usage: java printNames <namesFile> <numEntries>");
for (String s : args) {
System.out.println(s);
}
} else {
String filename = args[0];
int numEntries = Integer.parseInt(args[1]);
try {
doPrintNames(filename, numEntries);
} catch (FileNotFoundException e) {
System.out.println("There is no file named " + filename);
}
}
}
}Notes on fleshing out the Java program skeleton:
-
There are many possible strategies for translating
printNames.pyinto Java.-
The above program skeleton attempts as much as possible to preserve the “Pythonic” nature of the original program when translating it to Java, just to show that many Python programming patterns can be expressed in Java. Hopefully, this will make you aware of programming possibilities available in Java that you didn’t know about before.
-
This translation strategy does not result in program with customary object-oriented Java style. In particular the
printNamesclass does not have any instance variables, instance methods, or constructor methods, because no instances of this class will ever be created. TheprintNamesclass just serves as a repository for thedoPrintNamesstatic method that corresponds to theprintNamesfunction withinprintNames.py.
-
-
Remember that you can talk with your classmates about high-level approaches for fleshing out this skeleton, but should not share any Java code with them.
-
You may define additional helper static methods within the
printNamesclass. -
You may also define additional helper classes within the
printNames.javafile. These may be top-level classes (at the same level as theprintNamesclass; do not declare them with any keywords likepublicorprivate) or so-called “inner classes” defined locally within theprintNamesclass. -
You should not define any instance variables, instance methods, or constructor methods within the
printNamesclass. -
Because Java is statically typed and has explicit type declarations, it is necessary to decorate the program with many such type declarations. And because type constructors like
ArrayList,HashMap, andMap.Entrytake type arguments (in angle brackets), some of these types can become very complex. For example, the type of thenamesDicthashmap isHashMap<String,ArrayList<String>>. Java programmers sometimes try to avoid specifying type arguments by leaving them out, instead writingHashMaporHashMap<String, ArrayList>, along with possibly inserting explicit type casts in their programs. But this leads to compile-time warnings likeNote: printNames.java uses unchecked or unsafe operations. Note: Recompile with -Xlint:unchecked for details.This warning means that you should edit your program to correct the type declarations.
-
In Java it can be excruciating to specify a simple notion like “a pair of values”. In Python, the
.items()method on a dictionary returns a list of key/value pairs. Java provides something similar: theentrySet()method. This returns a set of key/value pairs, but the Java type system requires them to be instances of the typeMap.Entry, in this caseMap.Entry<String, ArrayList<String>>, which has getter methodsgetKey()andgetValue(). -
Java has a so-called “for-each loop” that iterates over all elements of a collection. Using this is preferable to writing a loop in terms of explicit iterators or explicit indices. For example:
for (Map.Entry<String,ArrayList<String>> entry : entriesPrefix) { ... }is equivalent to:
for (Iterator<Map.Entry<String,ArrayList<String>>> iter = entries.iterator(); iter.hasNext(); ) { Map.Entry<String,ArrayList<String>> entry = iter.next(); ... }It’s natural to translate Python
forloops to Java’s into thesefor eachloops. For more onfor eachloops, see these notes. -
For any sorting, you should use
Collections.sort. Unfortunately, Java does not have anything like Python’s key mechanism for specifying the order in a sort. Instead,Collections.sorttakes as its second argument an instance of any class that implements theComparator<T>interface. Such an instance provides acompareTomethod that takes two objectso1ando2of typeTand returns:- a negative integer if
o1should precedeo2in the ordering (i.e.,o1is less thano2); - zero if
o1is equal too2in the ordering; - a positive integer if
o1should come aftero2in the ordering (i.e.,o2is greater thano1).
So there’s a lot of overhead for specifying the order in a sort.
One way Java tries to reduce this overhead is by allowing so-called anonymous inner classes. Suppose you are trying to sort a mutable collection
thingswhose elements have type T.</a> Then usingCollection.sortas follows:Collections.sort(things, new Comparator<T>(){ public int compare(T s1, T s2) { ... } });is equivalent to first defining a so-called inner class within the
doPrintNamesmethodclass ThingComparator implements Comparator<T> { public int compare(T s1, T s2) { ... } }and then using
Collections.sort(things, new ThingComparator());This is similar in spirit to using an anonymous lambda function in Racket or Python rather than first naming the function and then using the function name. It makes sense to use anonymous inner functions in cases where there’s only one place in the code where instances of a class are created.
- a negative integer if
-
Google is your friend for finding relevant documentation/examples for classes used in this program. You needn’t cite “obvious” documentation sources (e.g Oracle’s Java documentation), but are encouraged to cite less obvious ones that were helpful for you.
-
Test your Java program on the sample input file names.txt for various values of
numEntriesto verify that it has the same behavior as the Python program. For example, executing the following lines in a terminal should give the same printed output as the examples shown earlier.javac printNames.java java printNames names.txt 10
c. Reflecting on Python vs. Java (10 points)
After you have finished implementing and testing printNames.java, reflect on comparing the two languages in the context of this particular example. What aspects of Python/Java made these programs easy or hard to understand or to write? For each of the two languages, list the all the features that either (1) helped you understand/write the program or (2) got in the way of you understanding/writing the program.
It is expected that you will be very thoughtful about this reflection. You should discuss both major and minor features, and give a detailed justifcation of each of your claims (along with sample program fragments, where appropriate). Feel free to discuss features with your classmates, but remember that you must do the write-up on your own, following the Gilligan’s Island rule.
Here are some specific things you are expected to cover in your reflection:
-
Syntax
-
Dynamic vs. static typechecking. Which language uses which? What are the advantages and disadvantages of these in the context of this program?
-
How easy is it to specify types in Java?
-
Compare how sorting is specified in the two languages. Which approach do you like better? Why?
-
How helpful is Java’s object-oriented nature in this problem?
-
Compare the data structures used in the two languages. Which do you think are easier to use. Why? Be specific, referring to particular aspects of the given program.
In the past, many student responses had claims that boiled down to “I’m more familiar with language A than language B, therefore B is inherently more confusing than language A”. Certainly, your own programming history will influence what you find confusing and difficult, but it’s important to step back and compare language features as if you were equally familiar with both languages. Imagine a similar claim about natural languages; it would be absurd for you to claim “English is a better language than Spanish because I’m a native English speaker and I’m just learning Spanish so find many features of Spanish confusing”.
3. Revenge of the Nerds (15 points)
Read Paul Graham’s essay Revenge of the Nerds and the follow-up article Re: Revenge of the Nerds. Write several paragraphs in which you summarize Graham’s arguments. Then explain, based on your programming experience, what you think of his claims. What do you think is insightful? What is baloney?
As part of the summary, you should address the following points:
-
List the features of Lisp that Graham thinks are important and explain why he thinks they are important. Which of these features are present in other languages that you’ve used? Which are not? Focus on the ones that are not and explain why Graham thinks they are important. Do you think they’re important? (Note: your answer at the end of the semester may be different than it is now!)
-
Graham uses ITA’s airline fare search program as an example. Are you convinced of his claims by this example?
-
What do you think of Graham’s argument about code size?
-
Explain Greenspun’s tenth rule. What does it have to do with Graham’s notion of expressive power of programming languages?
-
What do you think of Graham’s discussion of “pointy-headed bosses”, the worries they have, and how they make decisions?
4. Racket Evaluation (10 points)
For each of the following Racket definitions, write the value to which the variable will be bound, or “error” if evaluating this binding would result in an error.
Write your answers, with one line per definition, in order, in the form:
x |-> 7
y |-> 3
z: divide-by-zero errormeaning that variable x is bound to value 7, variable y is bound to value 3, and evaluating the binding for z results in a divide-by-zero error.
Predict the answers without running the code. You may find it useful to write evaluation derivations, leaving blanks for the result values as you build the derivation, and then filling in the results once you begin to reach values, but you do not need to submit any derivations in this problem. You may also check your manually evaluated answers by running each binding in order in the DrRacket REPL. (Instructions on using DrRacket are here.)
#lang racket
(define a 5)
(define b (* a a))
(define c (+ (* 2 a) (- b a)))
(define d (+ a b c))
(define e (+ a))
(define f (+))
(define g (*))
(define h b)
(define i (if (< a 0) 7 (quotient 43 a)))
(define j (if (= a 0) 11 (remainder 43 a)))
(define k (/ i j))
(define l (< a b))
(define m (= b c))
(define n (< b c d))
(define o (+ a m))
(define p (< a m) )
(define q (if a b c))
(define r (if l m n))
(define s (if (if (< i j) m l)
(if (> a c) (+ a c) (* a c))
(if (< a b) (+ a b) (* a b))))
(define t (= (if (< b c)
(* (remainder (- (* a b) (* 2 a)) c) (- (quotient d b)))
(* (- (+ d (* (* a b) (quotient d a))))))
(- (* (/ (- c a) (- a 1)) (quotient b (if (> a c) i j))))))
(define u (if (> i j) (< a 0) (< (< b c) a)))
(define v (if (<= i j) (< a 0) (< (< b c) a)))5. Big-step and Small-step Semantics (20 points)
The lecture on Racket expressions, declarations, and values introduces two models for evaluation of Racket expressions.
-
The big-step evaluation model shows the evaluation of an expression as an evaluation derivation tree in which the evaluation of the whole expression is determined from the evaluation of its subexpressions.
-
The small-step evaluation model shows the evaluation of an expression as an step-by-step process in which the lefmost redex (reducible expression) is evaluated on each step until there are no more redexes.
As an example, consider evaluating the Racket expression (if (< x y) (* (- y 10) x) (/ y 0)) in an environment env2 in which x is bound to 5 and y is bound to 17. Then one way to write big-step evaluation derivation of this expression is
| | x # env2 ↓ 5 [varref]
| | y # env2 ↓ 17 [varref]
| -------------------- [less-than]
| (< x y) # env2 ↓ #t
|
| | | y # env2 ↓ 17 [varref]
| | | 10 # env2 ↓ 10 [value]
| | -------------------- [subtraction]
| | (- y 10) # env2 ↓ 7
| |
| | x # env2 ↓ 5 [varref]
| -------------------------- [multiplication]
| (* (- y 10) x) # env2 ↓ 35
----------------------------------------------- [if nonfalse]
(if (< x y) (* (- y 10) x) (/ y 0)) # env2 ↓ 35In the above conclusion-below-subderivations format, each conclusion below a dotted line is justified by the subderivations above the dotted line. Another way to write this derivation is “upside down” using conclusion-above-subderivations format, where each conclusion at the top is justified by the bulleted subderivations below it:
(if (< x y) (* (- y 10) x) (/ y 0)) # env2 ↓ 35[if nonfalse](< x y) # env2 ↓ #t[less-than]x # env2 ↓ 5[varref]y # env2 ↓ 17[varref]
(* (- y 10) x) # env2 ↓ 35[multiplication](- y 10) # env2 ↓ 7[subtraction]y # env2 ↓ 17[varref]10 # env2 ↓ 10[value]
x # env2 ↓ 5[varref]
A small-step derivation sequence for this example is shown below. Curly braces have been used to highlight the redex in the expression at each step. Rules names in square brackets show the rule used to reduce the redex in the previous line to the result in the current line.
(if (< {x} y) (* (- y 10) x) (/ y 0)) # env2
⇒ (if (< 5 {y}) (* (- y 10) x) (/ y 0)) # env2 [varref]
⇒ (if {(< 5 17)} (* (- y 10) x) (/ y 0)) # env2 [varref]
⇒ {(if #t (* (- y 10) x) (/ y 0))} # env2 [less-than]
⇒ (* (- {y} 10) x) # env2 [if nonfalse]
⇒ (* {(- 17 10)} x) # env2 [varref]
⇒ (* 7 {x}) # env2 [subtraction]
⇒ {(* 7 5)} # env2 [varref]
⇒ 35 # env2 [multiplication]Despite differences between the big-step and small-step derivations, both are ultimately describing the same evaluation process, so they share lots of similarities:
- They evaulate the same subexpressions to the same values and get the same final result value for the whole expression.
- In both derivations, only the “then” clause of the
ifexpression is evaluated. This is a good thing, since evaluating the “else” clause(/ y 0)would give a division-by-zero error.
a. Big-step derivation (12 points)
Construct a big-step derivation for the following expression in an environment env5 with bindings a↦3, b↦6, c↦4:
(+ (if (< a b) (* a (+ b c)) (+ b #t))
(if (if (> a c) (< c b) (- c 3)) (* 2 b) a))You may use either the conclusion-below-subderivations format or conclusions-above-subderivation format shown above — whichever you prefer. Regardless of format, you should indicate in brackets which rule is being used at each step of the derivation.
b. Small-step derivation (8 points)
Construct a small-step derivation for the same expression as in part a in the same environment, using the same formatting conventions used in the small-step derivation example above. In particular:
- Each step of the small-derivation should evaluate the leftmost redex, which should be highlighted between curly braces.
- The result of each step should be annotated with the rule name (in curly braces) used to reduce the redex from the previous line.