Joins
One of the most important operations on relational databases is to join two tables, and one of the most important differences in usage between relational and non-relational databases is that in a non-relational database, joins are often avoided. For example, joins are harder when data is sharded. So, let's learn a bit about joins.
- Why Joins?
- Vet Office
- Join is dynamic
- Primary Keys
- Keys and Foreign Keys
- Joins
- Mappings
- Movie Directors
- Foreign Keys
- Backwards Representation!
- Misconceptions
- One-Many Relationships: Looking up Movie Directors
- Many-Many Relationships
- Represent Many-Many Relationships with an Intermediate Table
- Other Attributes in an Intermediate Table
- Looking up Acting Credits
- Flexibility of Joins
- Comparison with MongoDB
- More Comparison Between Relational and Non-Relational Databases
- Summary
Why Joins?¶
Joining is how relational databases represent things like lists. In a relational database, each row has a fixed number of columns, so variable-length quantities don't work.
Suppose we want to have a table of people and part of that information is their hobbies. Here are three documents as we might represent them in MongoDB:
{name: "Homer", hobbies: ["TV", "donuts", "beer"]}
{name: "Lisa", hobbies: ["reading", "saxophone"]}
{name: "Bart", hobbies: ["skateboarding"]}In a relational database, we might try to do something like this:
| Name | hobby1 | hobby2 | hobby3 |
|---|---|---|---|
| Homer | TV | donuts | beer |
| Lisa | reading | saxophone | null |
| Bart | skateboarding | null | null |
but this doesn't work well.
- what if someone has 4 or more hobbies?
- how do we count how many hobbies someone has?
- how do we find people who have a particular hobby?
- what order are the hobbies put in the table?
All of these issues are difficult or impossible with the representation above.
What we really want is something like a list. So, how can we do lists in the fixed-format of relational databases? One way to try is to have multiple rows:
| Name | hobby |
|---|---|
| Homer | TV |
| Homer | donuts |
| Homer | beer |
| Lisa | reading |
| Lisa | saxophone |
| Bart | skateboarding |
That pretty much works, but if we have a lot of information about the person (date of birth, SSN, address, occupation, salary, major, GPA ...) that ends up getting repeated in every row, which wastes space. There's also no single row that represents a particular person, which runs into issues as well, because if someone moves, we have to update all the rows that their address is in.
So our next approach is to store the person information once, in one table, and the hobby information multiple times, in a second table, and dynamically link the two tables together in a operation that is called a join.
Vet Office¶
Suppose each customer of a vet office has one or more pets. That is, we might think of a customer as having a list of pets.
Still, each pet will have a lot of information associated with it: a very
wide database row. That row will exist in a table where each row is about
a single pet. We might call that table pet. For example:
| Name | kind | weight |
|---|---|---|
| Hedwig | owl | 2.0 Kg |
| Scabbers | rat | 0.5 Kg |
| Crookshanks | cat | 5.0 Kg |
| Santa's Little Helper | dog | 10.0 Kg |
| Snowball | cat | 4.5 Kg |
| Snowball II | cat | 4.8 Kg |
We will have a separate table of owners, with their name, address,
phone number, how much they owe the vet office, and so forth. That
information will exist in a table where each row is about a single
owner. Each owner probably has an Owner ID number, which we will call
oid. We might call that table owner.
| OID | Name | address |
|---|---|---|
| 1 | Homer | 742 Evergreen Terrace |
| 2 | Harry | 4 Privet Drive |
| 3 | Ron | Ottery St Catchpole |
| 4 | Hermione | unknown |
Each pet will need to keep track of its owner by storing the OID of
its owner. So we the pet table actually has a column for that, so
it's really more like this:
| OID | Name | kind | weight |
|---|---|---|---|
| 2 | Hedwig | owl | 2.0 Kg |
| 3 | Scabbers | rat | 0.5 Kg |
| 4 | Crookshanks | cat | 5.0 Kg |
| 1 | Santa's Little Helper | dog | 10.0 Kg |
| 1 | Snowball | cat | 4.5 Kg |
| 1 | Snowball II | cat | 4.8 Kg |
Notice that Homer has two pets so his OID appears in the row for each of his pets.
So, to have a query that reports information on both a pet and its owner, we need to join the two tables. For example, to list the name of both the pet and its owner, we might do something like this:
SELECT owner.name, pet.name
FROM owner INNER JOIN pet USING (oid);The results might look like this:
MariaDB [cs304_db]> select owner.name, pet.name from owner inner join pet using (oid);
+------------------+-----------------------+
| name | name |
+------------------+-----------------------+
| Homer Simpson | Santa's Little Helper |
| Homer Simpson | Snowball |
| Homer Simpson | Snowball II |
| Harry Potter | Hedwig |
| Ron Weasley | Scabbers |
| Hermione Granger | Crookshanks |
+------------------+-----------------------+Thus the concept of a join is to combine two tables into one
Join is dynamic¶
Note that join is a dynamic or virtual operation. A join
"connects" one table with another (such as the owner and pet
tables) temporarily, just for the duration of one query. It uses
the underlying data structures, but it does not modify them.
The joined table can be used in the query, so listing the owner's name and address of cats might be:
SELECT owner.name, owner.address
FROM owner INNER JOIN pet USING (oid)
WHERE pet.kind = 'cat';Primary Keys¶
A primary key is a column (or set of columns) that uniquely identifies
a row. In the IMDB and the WMDB, there may possibly be more than one
"George Clooney," but there cannot be more than one row with
NM=123. NM is the primary key.
You can probably think of many examples of a key from real life. For example, social security numbers were invented as a unique ID for each American eligible for social security. Similarly, B-numbers at Wellesley.
A key does not have to be a number. Your email address uniquely identifies you.
(For maximum efficiency, keys should be short and fixed-length, but they need not be.)
Keys and Foreign Keys¶
The pet table needs a unique identifier for each pet. This will just be
an arbitrary number, unique to each pet. This will be a column in the
pet table; we'll call it pid.
Because the pid uniquely identifies a pet, the pid will be the
primary key to the pet table.
Similarly, the owner table needs a unique identifier for each pet
owner. We'll call that oid and it will also be the primary key for
that table.
Now, what connects those two tables? How do we know that Hedwig's owner is Harry, while Crookshank's owner is Hermione? The answer is that
each pet record will have the OID of the pet's owner
Because the OID is a key in another table, it's called a foreign key.
Note that the OID is probably not a key in the pet table. For
example, since Homer Simpson has three pets (Santa's Little Helper,
Snowball and Snowball II), each of those pets will have Homer's OID in
their records, to represent the fact that Homer is their
owner. Obviously, if three records in the pet table have Homer's OID
in them, the OID can't be a unique identifer for a row.
If you recall your terminology from math classes, the mapping between owners and pets is a one to many mapping, since each owner can have many pets but each pet has one owner.
(At least the "only one owner" is a rule as we have described this. Obviously, we could make room in our representation to have Marge Simpson as a co-owner of the Simpson pets, but we won't do that. We'll stick to this one-to-many (1:N) mapping.)
Joins¶
If we want a query that draws information from both the owner table and
the pet table at the same time, that's called a join.
Remember that joining is a virtual operation: the joining happens during a query and does not affect the representation of either table.
A join connects one table with another, say pet and owner.
A join connects a row of one table with a row in another, say "Crookshanks" and "Hermione", or "Santa's Little Helper" and "Homer Simpson".
The result of a join is a "wider" set of columns, drawing columns from both tables. Thus, it's as if we had one wide table with all the columns of the two tables, and we are selecting from that wide virtual table.
Which rows do we choose? If it's a join, we typically have a join
condition, which is a boolean condition that says that the row from one
table belongs with the row from the other table. For example, we want the
row where the data from the owner table is about Harry Potter and the
data from the pet table is about Hedwig.
Mappings¶
These connections (mappings) can be:
- one-to-one (rare)
- one-to-many (common)
- many-to-many (common)
We'll use this terminology a lot.
Movie Directors¶
In the WMDB, a movie has only one director, but a person can direct more than one movie.
This is a one-to-many (1:N) relationship
Here's a picture of some connections between Peter Jackson and three movies he directed (the three Lord of the Rings movies) and also Kathryn Bigelow and a movie she directed ("The Hurt Locker"):

Foreign Keys¶
We can implement a 1:N relationship by storing the key for the person (the director) in the row for that movie in the movie table:
| nm | Name |
|---|---|
| 1392 | Peter Jackson |
| 941 | Kathryn Bigelow |
| tt | director | Title |
|---|---|---|
| 120737 | 1392 | Fellowship of the Ring |
| 167261 | 1392 | Two Towers |
| 167262 | 1392 | Return of the King |
| 887912 | 941 | The Hurt Locker |
Backwards Representation!¶
- Compared to what we are used to in programming, this is backwards!
- We would usually represent a person and have a list of the movies they directed stored with the person.
- We don't have lists in relational databases.
- Here, the person has no list, but each movie has one director id
- The director id is a foreign key: a key in some other table
- Notice director can't be a key in the movie table, because there are repeats
- Director can be a key in the person table, since it's their ID (NM)
Misconceptions¶
This representation is the opposite of what we would probably do in most programming situations. Consequently, this a common misconception in this database class: you may be tempted to store a list of related items in a row when there's a 1-many mapping. But this is not how relational databases are intended to work.
In a one-many mapping, each of the many keeps a pointer to the one.
There are many reasons for this counter-intuitive situation. Here are a few:
- Database tables are most efficiently operated if elements are of fixed size. Storing a list of movies in the director would make that a variable-length field.
- It's efficient to look up something using its primary key. The primary key for the person table is the NM, so looking up the director of a movie is guaranteed to be efficient.
- Databases are implemented so that joins are as efficient as possible. (That doesn't make joins free, and some newer non-relational databases technologies eschew joins. We'll talk about those much later.)
One-Many Relationships: Looking up Movie Directors¶
So far, we've been using the following syntax for our joins:
SELECT owner.name, pet.name
FROM owner INNER JOIN pet USING (oid);This is a good, useful syntax in the very common case where both
tables have a column with the same name and meaning — in this
case, oid. A more general syntax is to use the WHERE clause to
connect a row in one table to a row in another. For example, to pair a
movie in the movie table with a person in the person table who is
the director of the movie, we could do this:
SELECT person.name, movie.title
FROM person, movie
WHERE person.nm = movie.director;That lists the names of movie directors and the titles of the movies they directed.
The relationship between movies and their directors is one-to-many, because each movie has 1 director (at least in the WMDB, maybe not in real life).
Many-Many Relationships¶
We now understand how to use join to handle one-to-many mappings, what about many-to-many mappings? Our prototypical example of that for this course will be acting credits. As you know, IMDB will tell you the cast of any movie (a list of people who act in that movie) and and the filmography of any actor (a list of the movies they have acted in). Together, those are a many-to-many mapping between people and movies.
Here's a diagram of two actors (Jimmy Stewart and Katharine Hepburn) and three movies they were in (It's a Wonderful Life, The Philadelphia Story, and The Lion in Winter). They were both in The Philadelphia Story.

Represent Many-Many Relationships with an Intermediate Table¶
With an intermediate table, we can represent a many-many relationship. The table holds pairs of foreign keys.
A pair (P,M) means that Person P acted in Movie M.
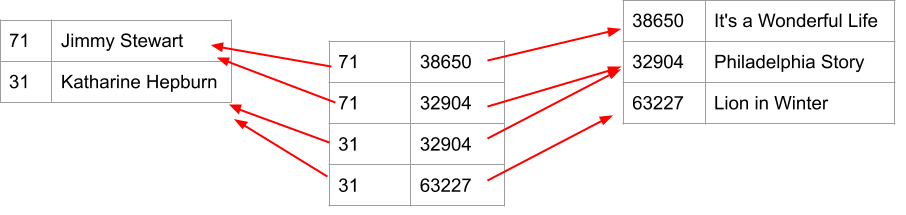
This intermediate table is called the credit table in the MySQL
version of the WMDB, but it doesn't exist in the MongoDB version.
Other Attributes in an Intermediate Table¶
We can add information to the intermediate table that belongs to the pair (P,M) rather than just to one or the other. For example, in the WMDB, we could store the name of the role that the actor played in that movie.
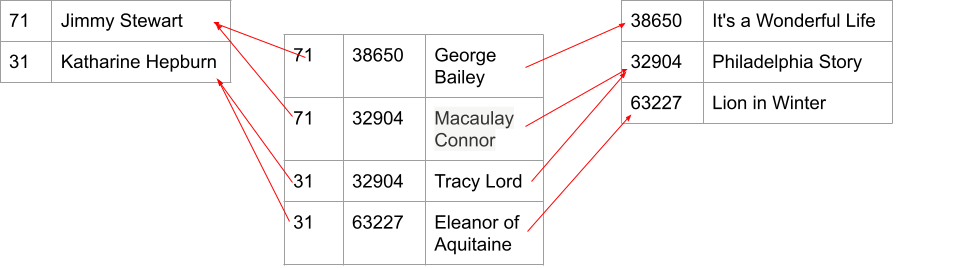
credit table. For example, Katharine Hepburn played
Eleanor of Aquitaine in "The Lion in Winter". The name "Eleanor of
Aquitaine" doesn't belong in either Hepburn's entry in the `person`
table, since she played many parts, nor in the "Lion in Winter" entry
in the `movie` table, since there are many roles in that movie. It
belongs to the pair.
What other attributes can you think of for the (P,M) pairs?
Looking up Acting Credits¶
To look up an actor's movie credits, we have to use all three tables. This time, though, the NM and TT fields are ambiguous, because they appear in both tables. So we have to use the table name in the expression:
SELECT person.name, movie.title
FROM person, credit, movie
WHERE person.nm = credit.nm
AND credit.tt = movie.tt;Flexibility of Joins¶
We motivated joins by considering them as a way to do lists, which otherwise don't fit the relational database model of tables with a fixed number of columns. But that's a very restrictive way of thinking about it. Joins actually give us some nice flexibility.
Consider that each movie has an addedby field that is a foreign key
to the staff table, giving the user id (uid) of the person who
added that movie to the database. Now think about a query like this,
which uses that field to match each movie with the staff member who
added it:
SELECT staff.name, movie.title
FROM staff, movie
WHERE staff.uid = movie.addedby;We could use that query to determine who added a particular movie, like this:
SELECT staff.name, movie.title
FROM staff, movie
WHERE staff.uid = movie.addedby and movie.title = 'Gravity';or we can use it to find the movies that someone added, like this:
SELECT staff.name, movie.title
FROM staff, movie
WHERE staff.uid = movie.addedby and staff.name = 'Scott';Thus, joins can give us a flexible way to use connections between entities.
Comparison with MongoDB¶
This is very different from our WMDB data in MongoDB. Some of the differences:
- we put the director's name into the movie document
- we put the cast of a movie into the movie document
- we put an actor's filmography (the list of their movies) into the actor document
In every case, in a relational database, we would dynamically retrieve this information by doing a join in the query.
Think about the redundancy here. If Peter Jackson has directed the
three Lord of the Rings movies, his information (name, nm, etc) is
stored in each movie he directed, so it's stored in three different
rows of the movie table. By doing a join, the information is only
stored once, in his row of the person table.
Storing the information redundantly means there's no need for a join when looking up information about the movie. The data is all in one place, and locality can increase speed and efficiency. In fact, if the director information were in a different shard, there would be increased network delays as we would have to go back out to the router and do another lookup.
Of course, redundant storage increases the size of the data, further bloating our documents. At a minimum, the DBMS would need more disk space for the redundant storage. In general redundancy might require scaling up the database, either vertically or horizontally.
Modern NoSQL databases like MongoDB were developed in part to explicitly make this tradeoff: storing data redundantly, in order to avoid joins and increase query speed, while taking advantage of cheap and plentiful storage (disk space).
Let's consider adding more data to the person information. What about Peter Jackson's birthplace, biographical data, home address, net worth, spouse, etc? Should that additional information be stored redundantly as well? Possibly. But now consider what happens when that data changes. We now need to update every place that the data is stored. Updates become much harder, and it's possible that some things will be out of date. Using joins, we can store the information in just one place, and updates are much easier and the data is consistent.
In general, we can decide to store some information in one place (say,
Peter Jackson's entry in the people collection) and store other
information redundantly (copying his name to every movie that he
directs or acts in). Since names change rarely and aren't that much
data, this is a good strategy, mitigating the disadvantages of
redundant storage while gaining the advantage of avoiding joins.
In creating the MongoDB version of WMDB for CS 304, we decided to
redundantly store the person's name (in the director and cast
parts of the movie document) but not the birthdate. This decision
means that each movie document has all the information you need to
generate hyperlinks to cast and director (for the Lookup assignment)
without the need for a join. If we later decided that the hyperlinks
also need the person's birthdate, our representation would not fit so
well and we might need to either redundantly store the birthdate or do
a join in looking up movie information.
Note that relational databases can also store data redundantly and they often do, and for the same reason as we did in MongoDB. The main difference is one of emphasis:
- in relational databases, the database is small enough to store on a single server and joins are implemented to be efficient and therefore data is typically not stored redundantly, while
- in a non-relational database, the data is often not all on the same server (in the same shard) and therefore avoiding joins is worthwhile.
More Comparison Between Relational and Non-Relational Databases¶
You can learn more about relational versus non-relational databases from the following links:
- comparison of terms and concepts
- pros and cons of relational and non-relational databases
- comparing MongoDB and MySQL
Summary¶
- joins are a virtual connection between two tables
- in a one:many mapping, each of the many specifies the one, typically with a key. Think of the director example
- a key uniquely defines a row in a table
- a many:many mapping is implemented with an intermediate table with pairs of foreign keys. Think of the credit example
- a foreign key is a key in some other table
- joins are common in relational databases and can avoid redundant storage