Relational Algebra
Relational algebra is the mathematical formalization of what happens in relational databases.
Based on Chapter 5 of Kiefer, Bernstein and Lewis or on Wikipedia article on Relational Algebra
Why?¶
Prior to relational databases, there were various kinds of databases (hierarchical, among others), but there was little regularity among them. The formalization of relational databases led to a big step forward in systematizing database technology.
Why is it still useful? Because it gives us a standard internal representation of a query that allows for query optimization: ways to re-write a query that are:
- equivalent, but
- quicker to execute
For example, consider the relative costs of executing the following:
ab+ac
a(b+c)
They are equivalent, but the latter is a lot faster to execute, because it only has one multiplication, while the first has two multiplications. The point is that algebraic manipulations of an expression can yield another expression that has the same results, but executes faster. That's how query optimization works.
From Figure 5.1:
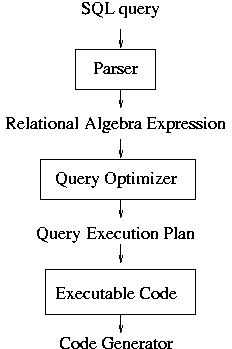
Defining Relational Algebra¶
Terminology
- relations - a relation is a set of tuples
- operators - take one or more relations as arguments and produce new relations.
The minimal relational algebra operators:
- Select: returns a subset of the relation, by choosing some of the tuples
- Project: returns a relation that has all the tuples, but only some of the columns. That is, tuple becomes a subtuple: each N-tuple becomes an M-tuple where M <= N.
- Union: returns the union of all the relations.
- Set difference: Returns the tuples that are in one relation but not in the other
- Cartesian product: AKA cross-product. The cross-product of relations A and B is a set of tuples where every tuple is the concatenation of a tuple from A and a tuple from B, for all possible pairs.
Note that to take the union (or intersection or difference) of two relations, the relations must be union compatible, which means they have the same number of columns with corresponding columns having the same datatype. The following two tables are union compatible:
CREATE TABLE elevation ( name CHAR(10), height INT );
CREATE TABLE population ( name CHAR(10), pop INT );Also, the Cartesian product is slightly different from the definition of cross-product in mathematics, but that will not concern us.
Additional (derived) operators:
- intersection
- join
- division (omitted, but if you're curious, read this on division
Notation¶
When working with relational algebra, we use special symbols to denote the various operations
- select: σcriteria(R): a greek sigma is like an "s" for "select"
- project: πattributes(R): a greek pi is like a "p" for "project"
- union: R ∪ S
- set difference: R - S
- cross product: R × S
- intersection: R ∩ S
- join: R ⋈condition S
You might try this exercise outside of class. We'll do some more exercises in class.
Write the relational algebra notation for our bi-coastal people.
Once you've found your own solution, click on the link to see one
possible solution. Assume we have the relations
Contacts(Name,ID) and
Addresses(ID,City,State)
Select¶
Given a boolean expression, we can select the tuples satisfying that condition:
σcrit(relation R)
Is a representation for
select * from R WHERE crit Project¶
SThis operation removes unwanted attributes (columns) from a set of tuples, like projecting onto a sub-space:
πA, B(relation R)
Is a representation for
select A, B from R Union and Intersection¶
These operations do exactly what you think: takes two sets of tuples and returns the union or intersection. They exist in SQL.
Union, denoted:
R ∪ S;
Is a representation for
select * from R union select * from S Intersection, denoted:
R ∩ S;
Is a representation for
select * from R intersect select * from S Algebraic Equivalence
One algebraic equivalence you can probably already guess is that
intersection is equivalent to using and in the where clause:
(select * from T where A) intersect (select * from T where B)is equivalent to
select * from T where A and BSet Difference¶
This operation also does exactly what you think it does: takes two sets of tuples and returns the difference. It exists in SQL.
Set difference, denoted
R - S;
Is a representation for
select * from R except select * from S Cross Product¶
This operation also does exactly what you think it does: takes two sets of tuples and returns the cross product. The cross product is flattened, though, so tuple (a,b,c) and tuple (1,2,3) yield tuple (a,b,c,1,2,3) rather than ((a,b,c,),(1,2,3))
Cross product, denoted:
R × S
Is a representation for
select * from R,S Join¶
This didn't have to be a primitive. It's a combination of cross-product and select:
R ⋈condition S
Is a representation for
SELECT * from R,S WHERE condition Query Optimization using Relational Algebra¶
The idea is to search a space of equivalent algebraic expressions, estimating the run time of each, and trying to find the minimum.
Some equivalences:
commutativity of select, which means we can select rows in either order of two conditions:
σcond A(σcond B(R)) ≡ σcond B(σcond A(R))
cascading of select, which means we can split up a conjunctive condition into multiple steps:
σcond A ∧ B(R) ≡ σcond A(σcond B(R))
cascading of projections, which means we can project out unwanted columns early. Note that X ⊆ Y and both are a list of column names.
πX(R) ≡ πX(πY(R))
cross products and joins are commutative
R × S ≡ S × R
cross products and joins are associative:
R × (S × T) ≡ (S × R) × T
selection and projection can be commutative if the relevant attributes are retained:
πX(σcond A(R)) ≡ σcond A(πX(R))
selection and cross-product (or join) can be commutative if the selection condition only applies to attributes of one relation.
σcond A(R × S) ≡ σcond A(R) × S
projection is commutative with cross product and join:
πX(R × S) ≡ πX(R) × πX(S)
Cost Estimation¶
Estimation of cost is done essentially with big-O notation, plus estimates of the number of tuples in different relations and in estimated results of sub-queries.
Examples:
- If you think a select will be very narrow and the other relation has an index, do the selection first and then look up the remaining tuples using the index.
Names of directors of movies named
Hamlet
- If you think a select will be very broad, and both relations are
sorted, do the join using the
mergesort
idea (see below) and ignore the index.
Names of directors who are under 50 and directed movies released after 1990.
or
Movies with a rating of at least 4 and with at least 5 listed cast members.
The Mergesort Idea¶
To find the intersection or union or difference of two sets, you need
to make sure there are no duplicates. In general, we are
merging
the sets. You can, of course, merge them and remove
duplicates afterwards, but it is often faster to remove them as we
merge.
One of the most efficient ways to remove duplicates is to sort, so that identical elements end up next to each other. Sorting is O(N log N), and most any other algorithm will end up being O(N2), as you iterate through one set, looking in the other.
The mergesort algorithm has two sorted subsets, and merges them in O(N) time to yield a sorted merger. We can use that idea to produce the union of the two subsets, the intersection, and so forth.
That is, we can arrange for an O(N log N) implementation for union, intersection, set-difference and other set operations.