AM4: Getting and processing the Data
The Wellesley Courses Data Feed
This section (until .$getJSON) is completely optional. It is to let you know how I created the JSON feed for the Course Browser. You don't need to do any of the steps here for AM4.
The Wellesley Courses website (https://courses.wellesley.edu/)
does not have an API or feed for allowing developers to access its data. To create the
JSON feed that we're using in AM4, we make use of a special command provided with Google
Spreadsheets, ImportHtml [see documentation here], which allows us to import in a Google spreadsheet every
table from an HTML page on the web.
The syntax for the command is simple, we call the function ImportHtml with three arguments:
the URL of the page, a value of "table" or "list" (depending on what we are scraping), and a number
that shows the index of the element on the page (in case there are several tables or lists).
You can try this on your own, by typing this line in the function input entry at the top of a Google spreadsheet:
=ImportHtml("https://courses.wellesley.edu/", "table", 0)
If we want to force the import to happen periodically, maybe every one hour, we can supply some code that requests this. Here is how the code for me looks like:

This command will read the content of the webpage and everything that is within the table will be imported to the spreadsheet. While this is good for us, the imported content also contains "junk" text that is usually invisible in the webpage, but that becomes visible here. This will require extra work from us to clean out undesired information.
Now that our data is in a Google Spreadsheet, we can use one of Google's APIs to access this content as a JSON object. The following steps are needed:
- Our spreadsheet needs to be public. To do this, go under File | Publish to the web ... and press the button "Publish" in the dialog box.
- We need the unique identifier of the spreadsheet that is part of the URL (see address bar of the spreadsheet).
- Generate a URL to access the JSON feed. For our spreadsheet, the URL will be:
https://spreadsheets.google.com/feeds/list/1035SQBywbuvWHoVof3G-VI0rapYJslaeYN5tTpNZq2M/od6/public/values?alt=json-in-script
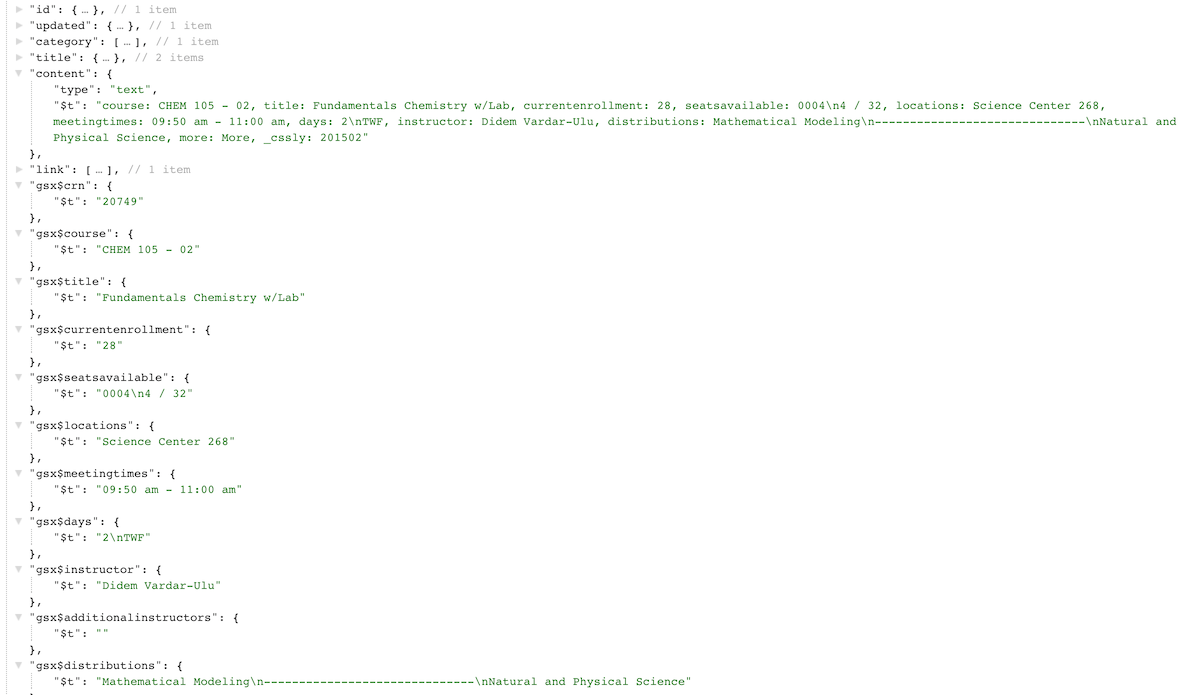
The screenshot below shows how the JSON-formatted data looks like. Every row of the spreadsheet
is converted into an entry object, an every column has become a property of the object.
Using $.getJSON
The JSON feed we created needs to be accessed from within our web application,
so that we can clean and process it to our needs. It turns out, the Spreadsheet API
for reading our feed doesn't support CORS, and we cannot use the function ajaxRequest that we
discussed in AM1. However, JSONP works.
How to know what method to use?
Sometimes, the APIs are not well documented, or it is difficult to find whether they support CORS or not. So, we will need to try both methods.
In this jsFiddle, I have shown the use of
both methods we have seen in AM1, ajaxRequest() that makes use of the XMLHttpRequest object, as well as jsonpRequest(), which injects a <script> tag in the DOM,
in order to invoke our callback function with the returned data.
To see that the ajaxRequest doesn't work, open the console and see the familiar error
"No 'Access-Control-Allow-Origin' header is present on the requested resource."
However, the jsonpRequest method
works and I have shown two different results, one without a specification for the format (the default
feed is in XML) and one requesting for JSON.
Having to go back and forth between these methods is not very convenient. Thus, we can make use of the jQuery library and its many methods for AJAX requests.
You can find a list of all the AJAX related methods in this page.
One can use the method $.ajax(), or $.get() and
$.post() for HTTP requests,
or even more specific methods such as $.getJSON() or .$postJSON()
that work with JSON data. The good thing about using such methods is that we can signalize
to try out the JSONP hack when necessary, by adding the argument &callback=?
in the request URL. This is exactly what we need to do for our Courses data.
var url = "https://spreadsheets.google.com/feeds/list/1035SQBywbuvWHoVof3G-VI0rapYJslaeYN5tTpNZq2M/od6/public/values?";
$.getJSON(url+"alt=json-in-script&callback=?",
function (response){
console.log(response);
items = response.feed.entry;
if (response.feed) {
console.log(response.feed.entry.length);
processCourses(items);
}
});
The first argument for this method is the request URL (where we added the format and the callback parameter), and the second argument is the callback function, which is invoked automatically, once the response from the server has arrived.
Organizing the data
The feed contains data in a format that is not immediately useful to us. We would like to have
data structures more suited to our needs. Given that we received the data from the $.getJSON
method discussed above, and the field response.feed.entry contains the 700+ courses,
the callback function processCourses can go through each entry and store the fields we
are interested in.
var cleanedCourses = {}// global variable
function processCourses(allCourses){
// 1. create an object that will store each course by its CRN
for (var i in allCourses){
var course = allCourses[i];
var crsObj = {'CRN': course["gsx$crn"]["$t"],
'Name': course["gsx$course"]["$t"],
'Title': course["gsx$title"]["$t"],
// more fields here
'Days': course["gsx$days"]["$t"].split("\n")[1], // clean up days
//continue with fields
};
//2. Add it to the cleanedCourses object, using the CRN value as the property name.
cleanedCourses[crsObj.CRN] = crsObj;
}
// other things
}
In the above-shown code, we show how we can create an object with properties the
fields of a course; do some cleaning of the text (see 'Days' property); and store
each object in the global variable cleanedCourses. We can think of this
variable as our container of all courses, where we can easily access a course by its
CRN.
Disadvantages of Early Cleaning [Added on 03/05/2015]
Splitting the field Days at the "\n" and selecting only the second element becomes problematic when there are multiple "\n" characters in the string, because the second element will contain only part of the entire string. Therefore, I have updated my code and provided more explanations in this new section about cleaning the data.
Once we have a variable such as cleanedCourses, and you access it in the console
(given that it's global), it will look as in the screenshot below:

Thus, we see all CRN values as "keys" in the container, and if we want what is
saved for each key, we invoke the variable: cleanedCourses["20005"] (or
whatever CRN value we are interested in). This will give us the content of the course,
as shown in the screenshot below:

Notice that the attributes "Cap" or "Free" were not present in the original data. They were created by processing the values in the field "gsx$seatsavailable".
One thing we can do with the data now is to iterate through the container keys and display the course title or some other information about the course. However, given that there are about 700+ courses, we might be interested in other ways for organizing the data.
Before doing that, it will be useful to explore the data, given that we are not familiar yet with its variability
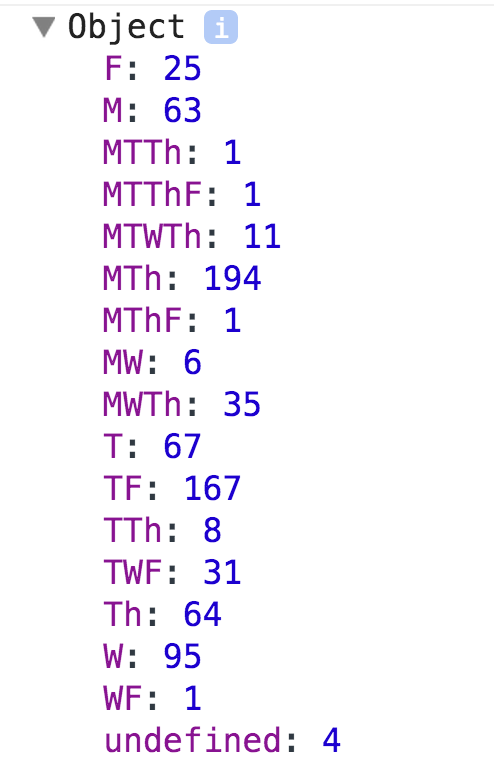
How to write code for exploring data? We can use the concept of "a counter dictionary". We group things together based on some value (the key for the dictionary) and count how many things are stored under each key. Below is some code that will group together our courses based on the values for the attribute "Days", as well as count the occurrences of every value.
//3. Calculate all different values for the field Days
var days = {};
for (var crn in cleanedCourses){
var d = cleanedCourses[crn]["Days"]; // get value
if (days.hasOwnProperty(d)) {days[d] += 1;}
else {days[d] = 1;}
}
console.log("Counts of day strings in the data: ", days);
The results of this code are shown in the screenshot below. We can notice that there is a certain variability in this data, coming from 17 different values for the field "Days".
This distribution is wrong! [Added on 03/05/2015]
Given that this distribution was created with the "cleaned" values for the Days field, it leaves out some values from the data. Therefore, consult the new distribution of values in this new section about cleaning the data.
This information is useful if we want to group the data in a certain way that allows us to search for courses occurring on a certain day or a combination of days. However, because there are so many combinations of values, it doesn't make sense to organize the data directly based on these string values (such as: 'MWTh', etc.). A more generic structure would be:
{
'courses offered once a week': {'Monday': [1001, 2001, 3001],
'Tuesday': [1010, 2010, 3010],
...
},
'courses offered twice a week': {'Monday, Thursday': [4111, 5111, 6111],
'Tuesday, Friday': [3555, 7555, 9555],
...
}
// the other cases
}
One can go even further and remove the names such as 'courses offered once a week' or 'Monday, Thursday' entirely, and only make use of numbers. This turns out to have many advantages, especially in making use of this structure by the user interface.
To go from the data in the current format (cleanCourses to this new structure,
we can replace the Thursday name 'Th' with 'R', so that now all days have one letter
symbols and then map the letters to numbers that correspond to the days of week: 1 for Monday,
2 for Tuesday, etc. In my code, this is how this new data structure looks like (there are two
functions that create this structure):
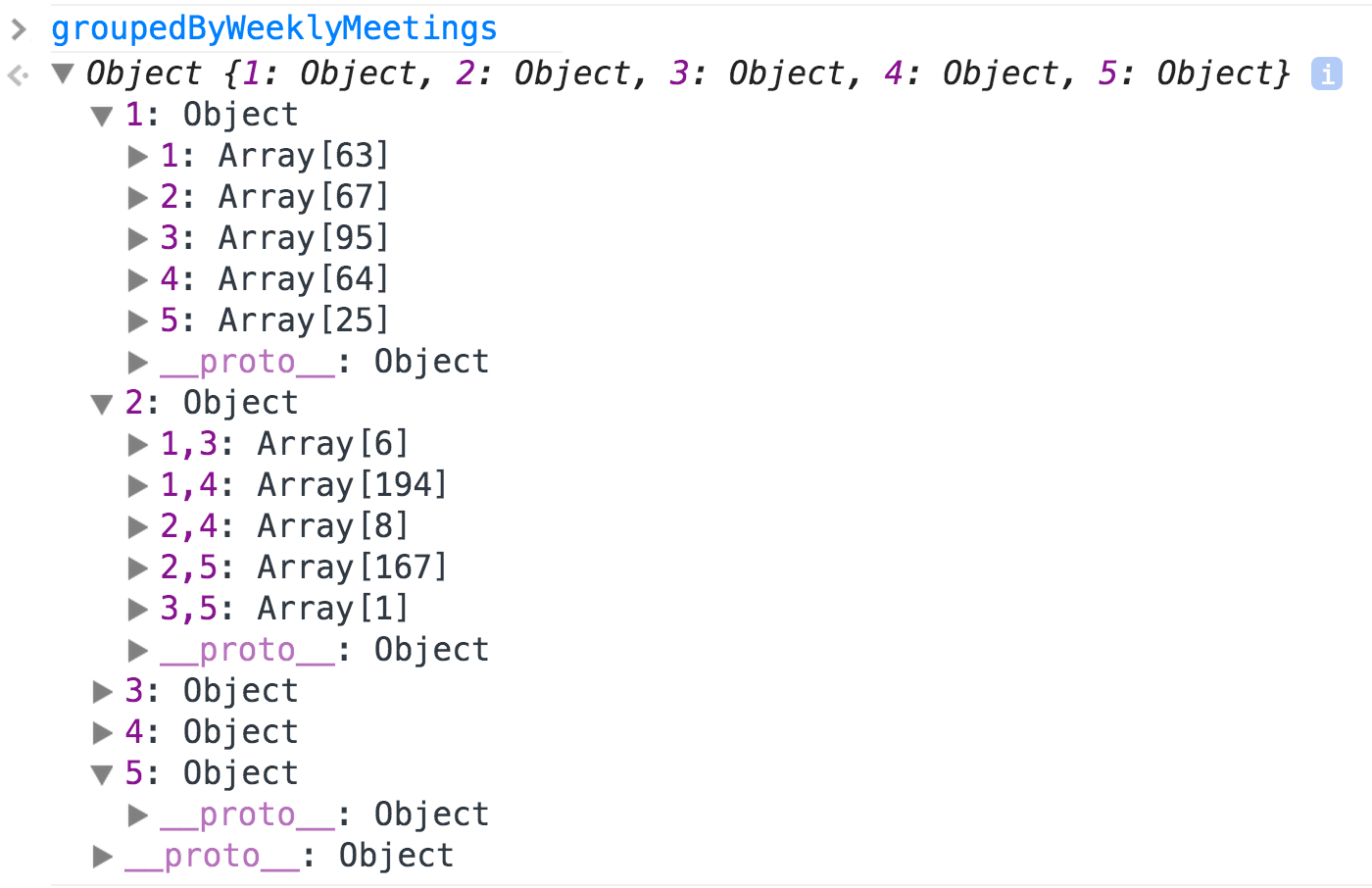
At the top level, the structure has five "keys" (or properties), corresponding to the weekly meetings that are possible (there cannot be more than five). However, because in the current data there are no five-day courses, the value for "5" is an empty object. Then, each of these properties has as a value an object that is also a container with keys, one for each day or combination of days. Thus, for courses offered once a week, we have all days: 1, 2, 3, 4, 5, and each of them is associated to an array of the CRN courses offered in that day. For courses that meet twice a week, we have a combination of two values, such as "2,5" (Tue + Fri), etc. And so on.
You can see how this structure is very useful in the screencast of a prototype that searches courses by days in which they are offered (next section).
Search by Days: A prototype
In the screencast, you see a working prototype for searching by days. Given that is a prototype, it only displays the titles of the courses (and not the complete course information). Otherwise, the prototype has several of the functionalities required for the AM4:
- There is a simple form to allow the user enter her choices. Based on a choice, the list of courses (if any) is shown, together with the total number of available courses.
- If one course is chosen (by clicking it), the course moves to the third column of "Chosen Courses".
- The user can remove courses from the "Chosen Courses" column, by clickin on the X mark.
This prototype was built with Bootstrap and the theme United from Bootswatch.
Here is the HTML code for the prototype. If you take the "blue pill", you can receive the two JS files as well.