
🏗 Project
Contents
- Roost Compiler Implementation Project
- Getting Started
- Collaborating and Working
- Compiler Output Requirements
- Programming Support
- Testing Support
- Documentation and Style
- Submission and Code Review
Roost Compiler Implementation Project
In CS 301, you will build a working compiler for the Roost programming language in several stages of a team project. This page links to each active stage and defines requirements and resources that apply to all stages, as well as instructions for initial and regular setup/submission/review steps.
General Reference
- Roost Language Specification
- Roost Example Code
- Tiny Compiler Exploration
- Tool Documentation (Git, IntelliJ, Scala, etc.)
- Policies on Resources and Collaboration for Project Work
Front End
Implement lexing, parsing, ASTs, name resolution/scope, and type checking.
- assign: Tuesday, 20 Apr
- checkpoint: Tuesday, 27 Apr
- checkpoint: Friday, 30 Apr
- checkpoint: Tuesday, 4 May
- checkpoint: Friday, 7 May
- due: Tuesday, 11 May
Feature
Add a non-trivial new feature to your compiler.
- assign: Tuesday, 18 May
- due: Friday, 28 May
Getting Started
The project assumes a Linux or macOS environment. If you are working on Windows, one convenient option is the Windows Subsystem for Linux (setup here), which basically provides an integrated Linux system inside Windows. Note WSL-specific instructions below.
IntelliJ and Plugins
Install IntelliJ IDEA CE, the Scala plugin, and a JDK if needed.
As you open files that are not Scala or Java files, IntelliJ may offer to install related plugins with a bar across the top of the editor pane. Unfortunately, the plugins it offers for JFlex and Java CUP are not useful to us. You should dismiss these offers by clicking Ignore extension.
One exception is the Markdown support plugin from JetBrains, which lets you preview the rendered Markdown in one pane as you write in another. I find typing becomes a bit laggy using the plugin, so I prefer to write Markdown in my usual text editor instead, but you may appreciate it.
If installing plugins, be careful of the plugin selection process. When there are multiple plugins in the window that pops up when you click the Install plugins option, you may need to uncheck those plugins that you do not want to install.
You may wish to try out IntelliJ IDEA’s Code with Me support for remote collaborative editing, which could make long-distance (or physically distanced, but local) pair programming more approachable.
Clone Your Project Repository and Open It With IntelliJ
- Check your email for an invitation to a GitHub repository your team will use. It has some starter code.
- Visit the web page for your team, click the green Code button
near the top right, and click HTTPS. Copy the URL.
- If you have setup SSH keys for GitHub, you can choose SSH.
- Clone this URL with Git and open the project in IntelliJ:
- Option 1: Clone on the command line (if you have Git installed):
- In a terminal, run
git clone URL, replacingURLwith the URL you copied. - Enter your GitHub username and password when prompted.
- You should now have a directory with the same name as your team, containing your project starter code.
- Open it with IntelliJ (File > Open).
- In a terminal, run
- Option 2: Clone the repository directly in IntelliJ
- In the IntelliJ menu bar, choose File > New > Project from Version Control. (Or, on a startup dashboard, choose Get From VCS.)
- Paste the URL in the URL text box and click Clone.
- Enter your GitHub username and password when prompted.
- Option 3: Connect IntelliJ directly to your GitHub account then clone the repository.
- WSL: If using Windows Subsystem for Linux, use
Option 1.
- Run
gitin the WSL command line to be sure you are cloning the repository in the WSL filesytem. - Use IntelliJ in Windows to open a project stored in the WSL file system.
- The project import may go differently from here.
- Run
- Option 1: Clone on the command line (if you have Git installed):
- Click Trust Project when asked if you want to trust the (BSP) project.
- IntelliJ should begin an import and build of the project. Wait a minute or so to make sure it wraps this up cleanly.
- Open the IntelliJ preferences/settings in the IntelliJ or File
menu.
- Choose Build, Execution, Deployment > Compiler.
- Enable Build project automatically.
- Optionally, in Languages & Frameworks > Scala:
- Enable Show type info on mouse hover …
- Choose Build, Execution, Deployment > Compiler.
Project Files
bin/: scripts, utilitiesroostc: wrapper to run the compilertest-roostc-status.py: basic testing script for test programs intest.
build.sc: build recipes for Millenv.sh: environment setup scriptlib/: jar files for external libraries and toolsmill: tool for managing Scala compilationroostc/src/: compiler source codetest/: Roost source files for testingREADME.md: top-level documentation of your implementation
Building the Roost Compiler
You can build the Roost compiler from IntelliJ or from the command line.
Build from IntelliJ
- Automatic builds:
- IntelliJ should usually compile Scala files automatically, shortly after you make changes. It generally will not run the lexer/parser generators automatically.
- Manual builds: click the green hammer in the upper right toolbar
or choose Build > Build Project from the menu bar.
- This will run the lexer/parser generators if necessary and do any other necessary compilation of Scala/Java code.
- This is also useful if IntelliJ seems not to respond to changes (sometimes IntelliJ gets sleepy?).
Build from the Command Line
If you prefer, you can build from the (Linux, macOS, or WSL) command line instead of using IntelliJ:
cdto the project directory.- Run
./mill roostc.buildto run lexer/parser generators and compile Scala/Java files, whatever is necessary to bring the build up to date.
Running the Roost Compiler
You will run your compiler and tests on the command line from the (Linux, macOS, or WSL) command line.
To configure your current shell session to find your Roost compiler as
roostc, use this command once in each new shell/terminal session:
cd <your-compiler-project-path>
source env.sh
The provided code includes a skeleton for the compiler’s command-line
interface. After the source env.sh step, you should be able to
invoke your compiler from the command line with
roostc. Usage for roostc can be seen with:
roostc --help
The wrapper script roostc simply launches invokes the
Java/Scala runtime with the right environment arguments to find and
evaluate the main entrypoint in roost.Compiler. All
command-line arguments to roostc are passed into your
compiler’s main entrypoint.
Collaborating and Working
Your team may collaborate however you wish, including dividing work or team programming, as long as everyone is contributing substantively. I definitely recommend starting with all team programming as you get a sense for what needs to be done. You may wish to try out IntelliJ IDEA’s Code with Me support for remote collaborative editing, which could make long-distance (or physically distanced, but local) pair programming more approachable.
Committing and Pushing Changes with Git
Your team’s work is hosted as a Git repository on GitHub, which is also where I will collect and review your work. Git will help you track changes and restore old versions if things go wrong. You have used Git if you have taken CS 240 (or some other classes), so it is likely somewhat familiar for most students, but this may be your first time working on a large protracted software project with version control.
As you work, you should frequently:
- Work together in pair/trio programming style with your team. This is the preferable mode of work.
- Communicate with your team (if you have to work separately) to avoid conflicts (concurrent edits to the same parts of the same files) and other broken merges (edits that change something the other teammate is depending on).
git addandgit commitcohesive sets of changes with a descriptive commit message.git pullcommits from – andgit pushcommits to – your team repository.
You can perform Git operations with command-line git or through
IntelliJ. (Or,
if you use Emacs, check out Magit!)
More reference:
- General Git Documentation
- IntelliJ Git Documentation
- GitHub Documentation
- GitHub Pull Requests for project submission, code review, and (optionally internal team coordination).
- GitHub Issues for tracking bugs, features, to-dos, etc.
- You can practice Git skills with the Tutorial from CS 240, even though you’re not in that course currently.
Tracking Issues and To-do Items with GitHub
At some point, your compiler may have a bug! At many times, you will have a wide range of tasks that need doing, such as debugging and fixing a problem, adding a new feature, redesigning and changing the implementation of an existing feature, updating documentation, etc. To help coordinate progress on these tasks and document the knowledge required (or discovered) to complete them, you find it useful to use the Issue Tracker hosted with your repository on GitHub.
Compiler Output Requirements
In addition to the specific requirements for each project stage, which may include outputs such as stage summaries enabled by command-line options or files generated by compilation, the following requirements for compiler output apply to the entire project.
Error Messages
Your compiler should detect and report the first error (lexical, syntax, name, or type errors) it encounters, if any. Reporting later errors is helpful, but not required. The compiler should print an error message, report its final status, and exit cleanly. The format and exact content of error messages is left to you. They must be informative and useful to the programmer in understanding and fixing the offending issue in the source code: it should be easy to fix the problem immediately after reading the message. It is highly recommended that you include a line and column number of a position in the input program source code where the error arises. This is helpful not just to your (for now imaginary) end users, but especially to you while you are testing and debugging your compiler.
Source code error reporting will be an important feature of your
compiler for lexical errors in this stage and many other types of
errors in future stages. One convenient way to organize
error-reporting is by raising instances of subtypes of
roost.error.CompilerError, an exception class. Whenever
the program encounters an error in source code, the relevant component
can raise an appropriate type of CompilerError exception. The
top-level compiler logic can then catch and report any CompilerError
in a single central location.
Status Reporting
Regardless of whether your compiler prints other required information as indicated by command-line options, reports a compiler error, etc., it must clearly report the final status of compilation upon termination. Your compiler must do the following two things to report whether it accepted or rejected the source program:
-
The last line printed by your compiler must always be one of
Accepted.orRejected., formatted on its own line. The output of your compiler must contain nothing else after this line. -
The exit code of the compiler process must be
0if the compiler accepts the source program and nonzero if it rejects the source program. Scala’s built-insys.exit(x)terminates the process and yields the given exit code,x.
These will be helpful for automating tests of your compiler.
No Other Output
Excepting any outputs explicitly required by each stage, compiler error messages, and status reporting, your compiler should print no other output under normal operation. If you wish to show additional information for yourself while developing, testing, or debugging, try the provided mechanism for explicitly enabling extra informational messages.
Programming Support
The starter code for roost.Compiler demos a few system
interaction features like working with buffered file IO and parsing
command-line arguments (using the
scopt) library). Your compiler must
implement at least the command-line options and status-reporting
behavior, regardless of how. Successive stages
will specify additional requirements of the same style. As long as you
satisfy these specifications, you may replace or change any parts of
the starter code.
Utility Code for Debug Messages
One feature of the provided code that you may find useful is support
for controlling the printing of informational messages from within
your compiler. As you develop your compiler, you may find it useful to
display more information about incremental internal steps than is
required (or allowed) by the output specification. The
roost.Util function provides a method debug for printing
such messages. This method has two useful features:
- It uses printf-style formatting, which is more efficient than
constructing strings through repeated concatenation with
+. - By default,
debugnever prints its messages. The command-line flag-d(or--debug) can be used to enable the messages when needed. This helps avoid the tradeoff between cluttering the compiler output and constantly adding/removing/commenting/uncommenting code to print such messages.
Using the -d or --debug flag with no additional argument enables
printing of all debug messages. Giving a comma-separated list of
debug keys as an argument to the -d or --debug flag enables only
the debug messages that are associated with this list of debug keys
and those messages that are associated with no key at all. The first
argument to debug is an option (None or Some(...)) indicating
how the message is keyed. The second argument is a format string. Any
remaining arguments are used to fill the % holes in the format
string.
import roost.Util
Util.debug(None, "#1. See line %d Debug messages are enabled!", lineNumber)
Util.debug(Some("lex"), "#2. Debug messages are enabled for key 'lex'!")
Util.debug(Some("parse"), "#3. Debug messages are enabled for key 'parse'!")Given the above Util.debug calls, running roostc
- without
-d/--debugdoes not allow any of the messages print; - with
-d/--debugallows #1 to print; - with
-d parse/--debug parseallows #1 and #3 to print; - with
-d lex,parse/--debug lex,parseallows #1, #2, and #3 to print.
This feature makes it attractive to leave your informational messages for all stages in place and enable only those that you need currently.
Feel free to add other broadly useful functionality in the
roost.Util object. You will likely import in most files.
Assertions
You should make liberal use of Scala’s assertion facilities: use
assert(condition, "message") to assert that specific Boolean
conditions (e.g., preconditions, postconditions, invariants) are
always true at run time, and otherwise intentionally crash with an
exception after printing message. Use assertions to check for logic
errors in your compiler code. Do not use assertions for reporting
errors in user input, such as command-line flags or Roost
source code. User input errors, such as Roost source code
errors, are an expected and normal occurrence for the Roost
compiler which must be handled by normal code in the compiler; they
are not logic errors in your compiler.
Testing Support
You must test your lexer. You should develop a thorough test suite that tests all legal tokens and as many lexical errors as you can think of. We will test your lexer against our own test cases and those of your classmates, using both lexically well-formed and lexically ill-formed inputs.
The starter code provides a basic testing script in
bin/test-roostc-status.py. For this stage, it expects
test inputs for this stage in test/lex/all/, where
tests are divided into tests the compiler should accept and those it
should reject. You should write dozens of tests for each stage,
mixing both kinds to ensure your compiler accepts programs that it
should and rejects programs that it should. Feel free to extend the
script (make your own copy, in case I update the original) to perform
more extensive testing
As we get into later stages, we will discuss adding more types of tests.
Documentation and Style
Follow the Scala Style Guide plus general rules of thumb for clean code, using your best judgment. Use assertions judiciously. Style matters more the larger the project gets.
Use Scaladoc header comments on classes and methods, especially for important parts of each stage. Use succinct inline comments to document steps of logic as need when they are not abundantly clear from the code.
Maintain an up-to-date README.md. It should include:
- documentation of how to build and run the compiler;
- a high-level description of your compiler design and implementation;
- documentation of any additional or non-standard features;
- justification of important design choices;
- a change log summarizing major changes in design or implementation (with dates);
- any critical known issues in your design or implementation.
Keep you compiler’s command-line interface self-documentation
(roostc -h or roostc --help) up to date but succinct.
Submission and Code Review
Commit and push your work to GitHub as you go. Each project stage includes a final stage deadline, when all parts of the stage are due, plus multiple intermediate checkpoints, when individual features from the full stage are due. After all stages and many checkpoints, I will test and review your code and provide feedback with the mechanisms described below. If useful, we can also schedule real-time code review sessions for more interactive feedback.
Submit a Checkpoint Pull Request
When you are ready to submit your work for a checkpoint or stage
deadline, you will push your commits to the relevant checkpoint branch
on GitHub, then create a GitHub pull request from that branch to the
review branch. The following instructions show every step of this
process.
- Find the checkpoint branch name on the individual
project stage page.
- Below, replace
CHECKPOINTwith this specific checkpoint branch name.
- Below, replace
- Prepare. Make sure your work is fully tested, committed, and pushed on
whatever branch you have been working on (likely
main). Visit the GitHub page for your project to confirm.- Below, replace
CURRENTwith this current branch name.
- Below, replace
-
Find or create the checkpoint branch. Above the upper left of the code listing on your project page, find the branch menu:
If your checkpoint branch already exists: select it in the branch menu and skip to the next step.
Otherwise, if you have not yet created the checkpoint branch:
-
In the branch menu, select your
CURRENTbranch in this menu if it is not selected. -
In the branch menu, enter the
CHECKPOINTbranch name in the “Find or create branch…” text box. -
(Replace
CURRENTwith the current branch andCHECKPOINTwith the checkpoint branch.)
Click Create branch: CHECKPOINT.
-
-
Create a Pull Request. Now you should see the
CHECKPOINTbranch name and an additional bar.
Click Pull Request. On the pull request page, select base: review and compare: CHECKPOINT. (Replace
CHECKPOINTwith the the checkpoint branch.)
- Complete the Pull Request.
Fill these three parts of the Pull Request (and optionally more):
-
On the right, click Reviewers and enter bpw (Ben Wood).
-
Choose a title including the checkpoint name.
-
Leave a brief message about the purpose of the pull request, plus any notes about anything I should know or look for while reviewing your submission. If the
README.mdalready covers this, the message will be short. Otherwise, include an overview here.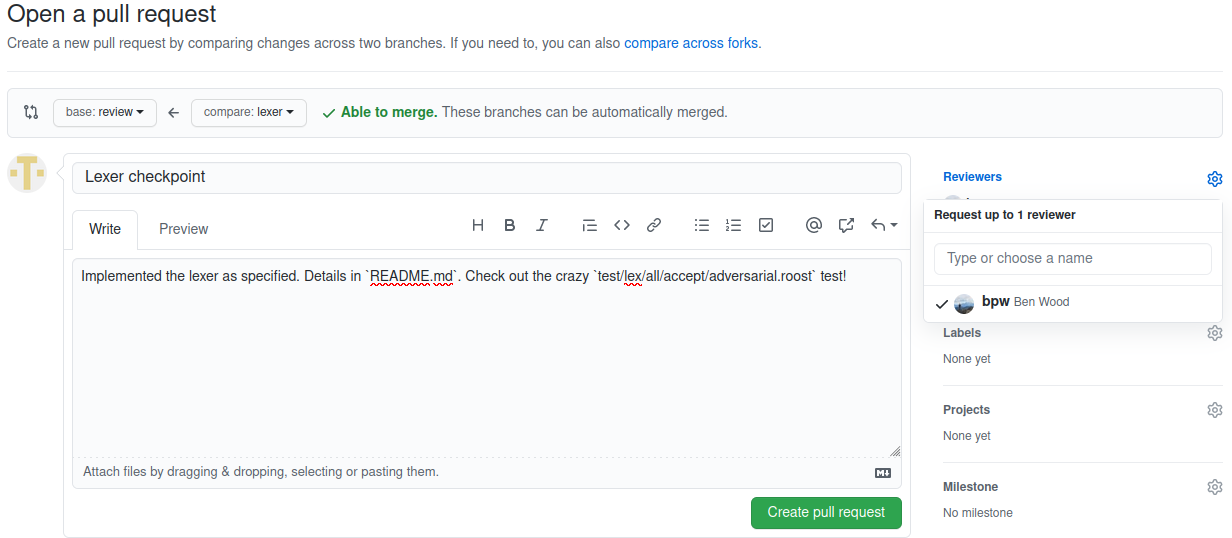
Click Create pull request. All set!
-
Add to a Pull Request Later
If you realize you need to include additional changes after submitting a pull request, you can take these steps. Please add only changes relevant to the checkpoint. (If in doubt, consult with me first.)
- Commit the new changes on
mainor another branch. -
Push the changes to the
CHECKPOINTbranch:git push origin HEAD:CHECKPOINTThis should work cleanly, assuming you have been following these instructions.
(Replace
CHECKPOINTwith the the checkpoint branch.HEADis the literal stringHEAD, referring to the most recent commit on the current branch.) - Find the existing pull request on the Pull Requests tab of your GitHub project page and enter a brief comment summarizing what has just been changed.
Bonus: If you prefer, you can use this command instead of using the GitHub UI to create the branch in the first place, too.
Reference and Other Workflows
You can refer to documentation on managing branches and creating a pull request with GitHub or general branching with Git if you want to understand more.
Unless all members of your team are experienced with Git, I
encourage you to work on the main branch and use the instructions
above. If your team is experienced with Git branching and prefers a
more interesting workflow (such as working directly on a “feature
branch” for each checkpoint), feel free to take other steps as long as
they result in a pull request from the CHECKPOINT branch to the
review branch. Please manage your branches cleanly.
Specifically, once you have submitted a checkpoint or stage by
initiating a pull request on its branch, do not commit new work for
other features into that branch. Continue development elsewhere so
that I am able to review the checkpoint without additional partial
work attached.
Code Review / Evaluation
Your work will be evaluated on the basis of:
- Completeness: Your compiler must implement all the required features for all language forms.
- Correctness: Your compiler must pass my suite of tests. I will evaluate your compiler on a private test suite plus all submitted tests of all teams.
- Efficiency and Scalability: Your compiler must employ appropriate data structure and algorithms that are effective from a big-O perspective and scale well to handle large programs.
- Design: Your compiler must make effective use of relevant foundations and be organized logically and clearly. (Moderate to big-picture view.)
- Style: See above.
- Documentation: See above.
These guidelines apply to the entire project.